


I’m excited to share Generational’s inaugural growth & late-stage company briefing with a deep dive on Scale AI, blending analytical rigor with feature writing. Disclaimer: I have a financial interest in Scale. Don’t take this as investment advice.
In this deep dive, you’ll learn insights from conversations with Scale’s customers, ex-employees, and competitors. I could do this thanks to Tegus, which centralizes expert calls into a single platform. Nothing beats primary research when it comes to understanding a company. If you’re curious about Tegus, try them out with this link.
Scale AI accelerates the development of AI applications through services and software. Its product suite has grown over time and can be mapped into the different layers of the AI stack: Data, Models, and Applications. Its core business is the suite of data solutions to collect, curate, and annotate high-quality data. Scale is trusted by top AI research labs (Open AI, Anthropic, Microsoft, Meta, Google, Cohere, Adept, NVIDIA) and the most iconic organizations as its customers (General Motors, Toyota, Etsy, Instacart, Chegg, US Army).
Why Scale AI is a generational company
One of the fastest growing tech companies. Since 2018, Scale has been doubling every year and reached $760M in annualized run rate in 2023
Trusted by the leading AI teams globally, including the top foundation model labs. This gives them a tailwind for the rapidly growing generative AI market
Unmatched scale of human & software operations to annotate data at scale. Customers consistently cite Scale’s ability to handle large projects as its unique advantage
Scale is consistently adding new products, even those that might cannibalize their core services business. This shows a willingness to keep innovating
Contents
1. Origins
The story of Scale AI started with a simple and amusing problem — Alexandr Wang suspected that one of his college roommates at MIT was stealing his food. And he wanted to build a smart fridge camera to catch the alleged thief.
To build the computer vision model powering the smart camera, he turned to tutorials on Google's TensorFlow, an open-source platform for machine learning. He copied the tutorial code for training models almost word for word. His challenge was getting a labeled dataset of food images that the AI algorithm could learn from. The only way to do so back then was to do it manually. After painstakingly labeling tens of thousands of images, Alexandr finally trained a model that performed well enough. This experience underscored his insight that data is the code. The latest algorithms to train models are mainly open-sourced and available for everyone. It is data that differentiates models.
Although this insight might seem like a stroke of luck, a closer look at Alexandr's past reveals a history of pursuing opportunities where he could gain these insights. Before enrolling at MIT in 2015, he already had top-tier Silicon Valley experience. He started his career right out of high school as a software engineer at Addepar, a wealth management platform based in Mountain View. At the same time, he was couch surfing across San Francisco, pitching various tech CEOs on why they should take a chance on him. He managed to convince Adam D’Angelo, CEO & co-founder of Quora, to take a chance on him with a classic Silicon Valley pitch — he was passionate about coding and would work through anything. After two years, Alexandr returned to MIT with the experience of improving the infrastructure performance of one of the world’s most popular sites. Many of his university peers then were still learning how to submit their first Github pull requests.
Even after returning to MIT, Alexandr continued working. During an internship at Hudson River Trading, he worked on building trading algorithms. At the same time, he continued to work on personal projects. During his first (and only) spring break at MIT, he flew to San Francisco right after finals to join Y Combinator. He eventually dropped out of MIT to start Scale.
The core idea that data is the code was born at MIT, but turning that into a product required more than just a good idea. It required the practical experience Alexandr had gained at Quora and the insights of co-founder Lucy Guo from her time at Snapchat. Both Snapchat and Quora relied heavily on outsourcing manual content moderation processes to handle images and posts flagged by users. The process of finding, hiring, and managing outsourced teams was cumbersome.
Based on these experiences, Scale was built to streamline the data labeling process with just a line of code. This innovation resonated with users, and the product quickly gained popularity. It topped Product Hunt. At that time, topping Product Hunt was more a sign of genuine user excitement for the product and less the result of a concerted marketing effort.
2. History
Phase 1: Building the Data Engine (2016-2019)
In its formative years, Scale dedicated its efforts to creating a straightforward API for training data. The company quickly became a preferred provider for autonomous vehicle (AV) companies such as Cruise, Nuro, Lyft, Uber, and Waymo, all of which have substantial data requirements. By successfully meeting these needs, the company established a strong foothold in the AV sector. This success allowed the company to broaden its services to encompass a variety of use cases, including natural language processing, e-commerce, and augmented/virtual reality. During this period, Scale earned the trust of leading AI teams, becoming their go-to provider for data.

Phase 2: Building the AI Engine (2020-2022)
Having established a reputation as a reliable provider of machine learning data, Scale turned its attention to the next challenge in AI development: managing the entire life cycle of AI development across teams. To address this, the company launched several new products, including Rapid, a self-serve data labeling tool. They also began offering fully managed models-as-a-service, partnering with customers to ensure they had the necessary infrastructure to deliver high-performing models. This expansion allowed Scale AI to grow beyond merely providing data to also managing the model, thereby broadening its market opportunity.

Phase 3: Generative AI and End-User Applications (2022-present)
Scale's close collaboration with OpenAI from the early days of GPT development gave them an insider's perspective on the foundational models that have driven the current wave of generative AI. In response to this trend, the company introduced new products tailored to Generative AI, such as Spellbook, a tool for comparing models and prompts. They also launched end-user applications like Donovan, designed to assist defense and intelligence professionals in decision-making. Another key initiative is helping enterprises build custom models. As an ex-Scale employee noted —
“One of the benefits of having started off in annotation space and having built a bit of a reputation for being a thought leader in AI is that you have customers coming to you with very specific business problems.” (Tegus)

3. Pain point
In the age of deep learning, data labeling has become an even more crucial aspect of training machine learning models to perform tasks with high precision. Data labeling, also known as data annotation, is the process of assigning labels or tags to raw data, such as images, text, or audio, to create a dataset that can be used to train and evaluate machine learning models. By providing models with labeled data, developers can help algorithms recognize patterns, learn from these patterns, and eventually make predictions or decisions based on new, unlabeled data.
In computer vision applications, images must be labeled with relevant information to help train models to recognize objects or features. For example, in a self-driving car project, photos of traffic scenes may be annotated with bounding boxes around vehicles, pedestrians, and traffic signs. The labeled data is then used to train a model to recognize and respond to these objects in real-time.
To achieve passable performance, tens of thousands of labeled images are often required for low-stakes use cases. At the same time, millions of examples are necessary for more nuanced applications, such as autonomous vehicles.
A good rule of thumb for dataset sizes is as follows:
10,000 labeled examples make a great dataset.
100,000 to 1 million labeled examples make an excellent dataset.
Over 1 million labeled examples create a world-class dataset.
Moreover, the need for labeling continues after initial training. Companies continuously strive to develop better models, and the ever-changing world requires models to adapt to new scenarios, such as learning new road signs in different countries.
While volume is essential, the quality of labeled data is more critical. In practical use cases like medical imaging, expert data labeling is required. Most people cannot read an X-ray image, requiring expert medical knowledge to label the data accurately. This can be expensive, with some companies paying $250/hour to a radiologist to label medical images. Quality assurance is still crucial even in trivial use cases like labeling cats in an image. A high-quality dataset is what distinguishes a model that appears to be randomly guessing and one that intelligently predicts outcomes.

Even for generative models, data annotation is required. As discussed in my note, Data Moats in Generative AI, most foundation models we interact with today go through a fine-tuning phase to make them follow human instructions — which is also data annotation.
Training foundation models like GPT-4 go through two main stages:
Pre-training: In this stage, the model is exposed to a broad array of text from various sources. This exposure helps the model to learn language patterns, context, and an understanding of different subjects. The pre-training phase is crucial as it forms the backbone of the model's knowledge. It's like teaching a child the basics of language and world knowledge before they can understand complex instructions.
Supervised Fine-Tuning (including RLHF): After pre-training, the model undergoes supervised fine-tuning, which includes techniques like Reinforcement Learning from Human Feedback (RLHF). This stage is akin to giving the model a specialized education. Here, it learns to understand and follow specific instructions, respond appropriately to queries, and refine its responses based on feedback. This stage ensures that the model is not just knowledgeable but also useful and safe in practical applications.
4. Products
Scale’s products can be segmented by layer of the AI stack (app/model/data) and by type (services/software).

Data
Scale’s data engine is a feat of software and operations. The company relies on a global workforce of around 240,000 people across Kenya, the Philippines, and Venezuela, managed through its subsidiary, Remotasks. These individuals provide the ground truth data essential to the company's success.
Training this diverse workforce, including many non-native English speakers, is challenging. Extensive training is necessary for understanding US road signs and mastering complex labeling tasks. This process is further complicated by high workforce churn. For example, the annual attrition rate in the Philippines is 50%.
Scale has developed software to automate the labeling process and review human work, resulting in a unique human-machine collaboration. Initially built with human annotations, machine learning models perform a first pass of labeling. This is then handed off to humans for review. If there's a significant difference between human and machine labels, the task is sent to more humans for further review. The company's ability to provide high-quality labels at scale and competitive pricing has drawn comparisons to Amazon.
Services
Rapid is a self-service data annotation platform designed to expedite the production of high-quality labels. It allows users to upload their data, select or create an annotation use case, and utilize Scale's workforce to receive labeled data quickly.
Pro is a robust data platform designed for businesses leveraging AI. It allows users to initiate labeling via an API, work with dedicated Engagement Managers for customized project setup, label large volumes of data, including complex 3D and Sensor Fusion data formats, and guarantee the highest quality labeled data.
Test & Evaluation services involve continuous testing of LLMs to identify and mitigate risks. Red teaming, a key component, simulates adversarial attacks to uncover and address system vulnerabilities.
Software
Studio is a comprehensive labeling platform that enhances the efficiency of a customer’s labeling team. It supports customers who prefer to label data in-house, offering tools to manage data, define annotation use cases, oversee project progress, and track labeler performance.
Nucleus is a data management tool for machine learning that helps improve model performance by visualizing datasets, ground truth, and model predictions. It also allows for curating interesting slices within datasets for active learning and identifying critical edge cases.
Models
Services
Custom models offering is designed to build, manage, and deploy large language model applications. This product focuses on fine-tuning large language models for improved performance on specific use cases. They allow customers to customize models to their particular use cases.
Software
Spellbook enables teams to deploy production-ready large language model-based applications in minutes. It allows users to create and compare prompts and provides features for evaluation and comparison. Spellbook is a prompting IDE built by Scale that will enable users to go through the entire pipeline of creating and comparing prompts.
Generative AI Platform is a full-stack solution that allows businesses to customize, build, test, and deploy enterprise-ready Generative AI applications. It enables the comparison, testing, and fine-tuning of pre-trained base models from various providers, such as OpenAI, Anthropic, and Google. It can be deployed in a company's Virtual Private Cloud (VPC) or hosted by Scale.
Applications
Forge allows marketers and brands to create AI-generated images of their products. This tool helps create visual content for advertising campaigns, social media, and other promotional materials. With Scale Forge, users can generate various images, such as products in different scenes or with other products.
Donovan supports decision-making processes within the defense and intelligence sectors. It can analyze structured and unstructured data, quickly identifying trends, insights, and anomalies. Donovan also offers advanced summary and translation capabilities, reducing the time needed for manual translation and auditing.
There is a slew of partially launched or sunsetted products like Synthetic, Document AI, E-commerce AI, Chat, etc. Scale likes to experiment with new products and see which ones get traction.
5. Leadership & Team
Alexandr Wang (Founder and CEO) - founded the company as an MIT dropout and became the youngest self-made billionaire. He started Scale with Lucy Guo, who left the company in 2018.
Dennis Cinelli (CFO) - Before joining Scale, Cinelli held several senior roles at Uber, including Vice President and Head of Mobility for the U.S. and Canada. His tenure at Uber also included serving as the Global Head of Strategic Finance, where he supported Uber's 2019 IPO. Cinelli's extensive experience in finance and technology includes positions at General Electric, GE Healthcare, Wabtec, and Aflac,
Arun Murthy (CPTO) - He joined the company with a rich data and product management background, having co-founded Hortonworks and served as its CPO before its merger with Cloudera, where he also held the CPO role. Murthy's experience extends to being one of the original members of the Hadoop team at Yahoo.
I don’t have an accurate count of Scale’s employee base. They laid off 20% of their ~700 employees in Jan 2023. According to LinkedIn, they have grown 70% since then. This puts their employee count at over 1,000. But Scale’s website still says they have 600 employees.
6. Market
Scale’s market opportunity can be divided into its core AI services market and select generative AI markets as its new growth vector. During its early days, Scale focused on data annotation but grew to be a fuller AI IT service provider, helping companies build production models over time. In 2023, this is a $27B market growing 20+%. This isn't particularly impressive given the competitive nature of the services market, the absence of a winner-takes-all dynamic, and the low margins.
But with generative AI, Scale’s market opportunity expanded and accelerated. They are the preferred data annotation vendor for top foundation model labs. This positions them to help enterprises build custom generative AI models. Releasing their Generative AI Platform and select apps like Donovan gives Scale another growth vector — a market that will almost double yearly to $55B by 2027.

7. Competitors
Scale’s core data annotation business is a competitive category with a long tail of vendors. Below is a select list of venture-backed competitors. This list excludes pure software providers, like Hasty (acquired by Cloud Factory), Dataloop, and Snorkel, and those focusing on particular modalities like Encord and v7 Labs for computer vision. While there are a lot of competitors, an ex-Scale senior employee commented that there hasn’t been a flagship customer that they’ve lost to customers —
“I’ve looked at all those companies at some point, and I’ve never really seen on the data annotation side anything that would tell me that they’re going to do better for the enterprise side. And I mean, I spent 14 months in that space, I haven’t really seen any one of them take off or really grow dramatically…And I don’t think I recall any impressive Scale customer leaving to go to any of them.” (Tegus)

Based on customer conversations, Scale remains the trusted resource by top AI teams because of its ability to process data at high quality and throughput. This is what convinced one of Scale’s flagship customers to move away from competitors —
“[We moved] most because of two things. One is the quality of the labeling. And the second one is the throughput…We also looked at the pricing of other solutions. Scale AI is still quite competitive in this market.” (Tegus)
Another flagship customer noted Scale’s breadth of product offering as something competitors can’t match —
“Do you know why I love Scale? Because it allows me to reduce the time of working with 15 other companies and can just work with one company. And I know that I have many features within this company…Other companies are more focused on labels or pipeline deployment of labels or managing the datasets or creating some synthetic data or providing the taskers to label your images or programmatically provide all of it. So it's more features-oriented versus Scale is across all of the different features. .” (Tegus)
As Scale becomes more of a software company, it will directly compete with C3 and Palantir. Scale’s recent focus has been on servicing the US government, having won a $250M contract with the US Department of Defense.
C3 (NYSE: AI, Mkt. Cap: $4.4B) is rooted in its IoT origins of building custom solutions for industrial and energy companies like Shell. C3 AI went public in December 2020 and has been pursuing its strategy of building a growing library of industry solutions, forging deep industry partnerships, running in every cloud, and facilitating reuse through standard data models. It now has solutions for industrial processes, supply chains, sustainability, financial services, and the public sector.
Palantir (NYSE: PLTR, Mkt. Cap: $55.4B) is rooted in building applications for complex, high-value government and commercial use cases. The company went public in September 2020 and is broadening its market appeal across industries beyond the government. The company's product platform includes Gotham, Apollo, and Foundry. Gotham is designed for the intelligence community to identify patterns within datasets. Foundry is the commercial counterpart of Gotham. Apollo is a platform that allows customers to deploy their software in any environment.
8. Financials
Scale’s ARR (annualized run rate, not recurring revenue) has been growing 114% every year since 2018. Last year, ARR grew 162% to $760M. This was driven by the foundation model labs’ need for human alignment and expertise.
Scale’s gross margin is around 50-60%, lower than 75% for the average software company. This is because of the heavy service component of data labeling.

9. Valuation
Scale was last valued at $7.3 billion when it raised a $325M series D in 2021. ARR quadrupled since then, along with a generative AI tailwind.
The exercise of valuing Scale here is to sketch how public investors might view them and not calculate an exact target price typical of equity research reports. There is not enough data to do so. There are only unconfirmed ARR and gross margin figures. If you are considering investing in Scale as a private company, factor in premiums and discounts for preference stack, major shareholder control, illiquidity, etc.
The most direct public comparables are C3 and Palantir, which are service-driven AI software companies. The comparison is imperfect because Scale engagements do not necessarily lead to recurring revenue - once the data annotation project is done, it is done. C3 and Palantir are building customized software for their customers, which becomes recurring revenue by licensing it for continued use. Data labeling company Appen would have been another comparable, but the market severely discounted their stock price after losing a key contract with Google, representing a third of their revenue. Another comparable group would be IT services companies like Accenture, IBM, Infosys, and Cognizant, whose project-based business models more reflect Scale’s. However, these companies have low single-digit growth compared to Scale’s >100% CAGR over the past few years. If Scale decides to go IPO, what valuation it’ll get depends on what narrative the investors buy into.
Narrative 1: Scale is a high-growth service-driven AI software company. Comparable group: C3 and Palantir (11-18x NTM ARR)
Narrative 2: Scale is an IT services company with limited long-term growth. Comparable group: IT services (2-4x NTM ARR)
Narrative 3: Scale is a high-growth services company with the potential of having better margins. Comparable group: Median software company as a proxy for something in between narratives 1 and 2 (6-7x NTM ARR)
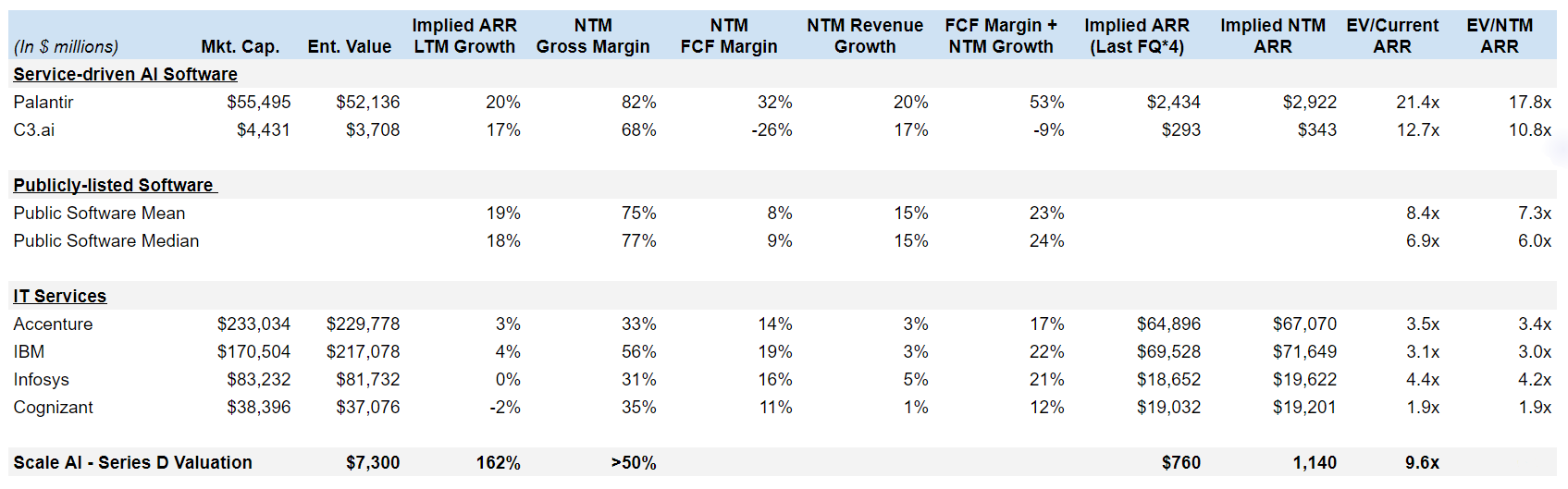
Public market investors put a high premium on growth and AI. Despite having a positive 15-20% rule of 40/R40 metric (NTM growth + FCF margin), IT services companies are valued at 2-4x NTM ARR. This is substantially lower than C3’s 11x NTM ARR despite having a negative 9% R40 metric. With Scale’s growth rate and market position, public investors will likely assign higher multiples to Scale around 11-18x NTM ARR. In a downside scenario, Scale might be valued as a median software company at 6-7x NTM ARR.
10. Key Debates
How much of their revenue will be recurring? The more recurring it is, the higher the margins and the more it will be valued like a software company. Scale only recently started selling end-user applications, its GenAI platform, and building custom LLM models for customers. This coincides with a competitive environment where startups, IT consultancies, and big cloud providers are all heavily investing in generative AI.
What is the longevity of Scale’s core data business? Using AI to annotate data, partially or entirely, is a growing trend. Using GPT-4 as the final evaluator of other models is common practice because GPT-4 beats the average human across many tasks. A study by the University of Zurich reveals that zero-shot ChatGPT outperforms crowd-workers and even trained individuals in annotation tasks. While human-annotated ground truth data is still considered the gold standard, it is feasible that a multimodal GPT-5 or the next-gen Mistral model could replace humans across many annotation tasks in 2024.
A counterpoint to this is that foundation models require regular fine-tuning because data distributions will change. ChatGPT already showed performance degradation, with many users noticing it has become lazier. With change comes fine-tuning to maintain its usefulness for users.
If scale ai can raise private valuation at $14B, what would their valuation be when they go public?
What is scale ai valuation now?