


The deep learning wave of the early 2010s led to a surge of data-hungry products. These products needed so much data that gathering it requires significant investment. So, the business community started honing the idea of data as a strategic asset and a business moat. As the Economist put it in a 2017 issue, “The world’s most valuable resource is no longer oil, but data.” This essay discusses data moats in today’s context of generative AI, which is driven by models that are exponentially more data-hungry. But first, what is a data moat? what is even an “AI product”?

A framework for data moats
A data moat is a strategic advantage a company gains by accumulating unique data that competitors cannot easily replicate, allowing it to deliver better products to customers. There are three vectors to it, each reinforcing one another.
Data flywheel: This is a self-reinforcing cycle where initial data collection leads to improved AI models, enhancing user experience. Better user experiences attract more users, leading to more data collection. Over time, this cycle continually upgrades the quality of the AI model and the user experience.
Data is proprietary: The uniqueness of a company’s data is central here. It’s not only about having exclusive data. It’s about how difficult it is for competitors to gather a similar dataset to deliver the same experience to customers. This can be achieved in different ways:
Commercial lock-in: Commercial agreements that guarantee exclusive data access
Data scale: Sufficiently big data corpus that discourages competitors
Regulated data: Regulatory frameworks and government procurement processes that limit access to data
Product experience is hard to replicate: This aspect emphasizes that it's not just the AI models, but the entire product experience enhanced by these models that create a data moat. Even if the data or model is somewhat replicable, competitors can’t replicate the same experience.
Netflix's recommendation system is a classic example of a product with a data moat. Netflix's data moat is tied to the exclusive content library it has built over the years. Even if competitors could theoretically build the same model and have access to the same user data - which is possible since Netflix allows customers to download their clickstream data - they won’t have Ozark, House of Cards, Black Mirror, Stranger Things, Narcos, Squid Game, and more. As users watch more Netflix, more data is collected to refine the recommendation system further. The result is a highly tailored user experience that is difficult for competitors to match.
Here’s a slide that captures the framework visually.

Defining AI products such as ChatGPT
An AI product is defined by its core value delivered by an AI model. In simpler terms, if the AI model is removed, the product loses its appeal or functionality. Consequently, a generative AI product uses a generative AI model. A quintessential example of one is ChatGPT. Without the underlying GPT model, which is GPT-4 today, ChatGPT would be just an empty chat interface. In contrast, a non-AI product like a spreadsheet retains its utility even without AI enhancements. Given the popularity of ChatGPT, we'll use it as the case study.
To evaluate ChatGPT against the framework, we first need to understand how GPT-4 is trained and what user data OpenAI collects.
Data OpenAI collects from ChatGPT users
According to OpenAI's privacy policy, when users talk to ChatGPT (or DALL-E), OpenAI has the right to use the chat logs to refine their models. Users have the option to opt out of this. However, this choice only impacts future interactions. Data from past conversations remains accessible to OpenAI. Even if you convince OpenAI to delete all of your data, which is right under CCPA, it is impossible to remove your data embedded inside a foundation model. In addition to chat logs, OpenAI gathers a lot of other information, similar to other software products. These are used for standard processes, such as processing payments, troubleshooting, and stalking users.

How does data feed into ChatGPT?
ChatGPT uses a version GPT-4 that is specifically tuned (including prompting) for conversations. It won’t produce the same output as the base GPT-4. But for this section, we focused on GPT-4 because there is public information about how it was trained and that the concepts apply would still apply to ChatGPT, and generally any generative AI product.
Training foundation models like GPT-4 go through two main stages:
Pre-training: In this stage, the model is exposed to a broad array of text from various sources. This exposure helps the model to learn language patterns, context, and an understanding of different subjects. The pre-training phase is crucial as it forms the backbone of the model's knowledge. It's like teaching a child the basics of language and world knowledge before they can understand complex instructions.
Supervised Fine-Tuning (including RLHF): After pre-training, the model undergoes supervised fine-tuning, which includes techniques like Reinforcement Learning from Human Feedback (RLHF). This stage is akin to giving the model a specialized education. Here, it learns to understand and follow specific instructions, respond appropriately to queries, and refine its responses based on feedback. This stage ensures that the model is not just knowledgeable but also useful and safe in practical applications.
While much has been written about the quantity of data, the quality of data is equally, if not more, important.
Quantity: The sheer volume of data is a fundamental factor in training robust models like GPT-4, which was trained on 13 trillion tokens (~2,300 Wikipedias). A large dataset ensures a broad base of knowledge, enabling the model to understand and generate a wide range of content. This extensive exposure allows the model to be versatile and handle a diverse array of topics.
Quality: This encompasses several aspects:
During pre-training: It includes the representativeness of the data, ensuring it covers a wide range of domains and perspectives. It also involves the freshness of content, as outdated information can lead to irrelevant or incorrect responses. Deduplication is important to prevent bias towards over-represented topics, while toxicity filtering ensures the model doesn't learn harmful or biased patterns.
During fine-tuning: Quality here focuses on the relevance and clarity of the instructions given to the model, as well as the diversity and complexity of tasks. This ensures that the model can handle a wide array of instructions and generate responses that are not just accurate, but also nuanced and context-aware.
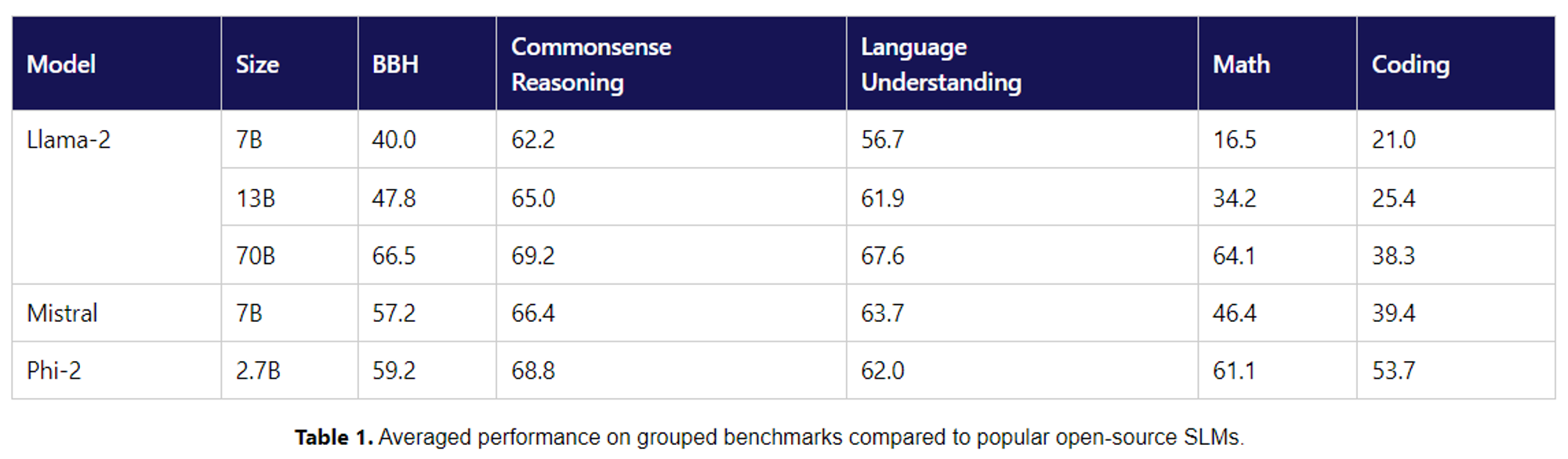
Research has shown that small high-quality, textbook-like datasets can lead to high-performing models. For example, Microsoft’s 2.7 billion parameter Phi-2 model trained on 1.4 trillion tokens nearly matches the performance of the Llama-2 70B, a model with 26x more parameters trained on ~2x more data.
Is there a data flywheel?
Pretraining phase
Although chat logs from over 180 million active users comprise a large dataset, they are not suited for the pre-training GPT-4. The reason is that these interactions are primarily users asking ChatGPT for information, rather than contributing new knowledge for GPT-4 to learn. Additionally, if my experience mirrors the typical user's, these conversations are likely riddled with typos and grammatical errors, further diminishing the quality of this data for pre-training. In short, chat logs constitute low-quality data for pre-training.
Fine-tuning phase
During supervised fine-tuning, chat logs become more useful but in a roundabout way. Fine-tuning mostly uses single-turn dialogues to learn what the ideal response is: someone asks a question and ChatGPT answers. But we can't use these chats directly as ideal answers because it’s just ChatGPT responding. There is no good feedback mechanism (yet). For example, if I ask ChatGPT to explain AI Transformers, the answer might be a hit or miss depending on who’s asking. Some might find it too basic, others too complex. Figuring out the 'just right' answer for a broad user base is tough, especially when few use thumbs-up/down feedback.

Instead of being used directly as fine-tuning data, chat logs are valuable by showing what users are looking for in ChatGPT. OpenAI sorts these chats into different buckets, called 'content categories.' These allow OpenAI to focus on creating fine-tuning datasets for categories that matter to users. For each category, OpenAI writes rules to steer GPT-4 towards good responses and away from the risky ones. Here’s an excerpt from the GPT-4 paper:
One of our main tools for steering the model towards appropriate refusals is rule-based reward models (RBRMs). This technique uses a GPT-4 classifier (the RBRM) to provide an additional reward signal to the GPT-4 policy model during PPO fine-tuning on a subset of training prompts. The RBRM takes three things as input: the prompt (optional), the output from the policy model, and a human-written rubric (e.g., a set of rules in multiple-choice style) for how this output should be evaluated. Then, the RBRM classifies the output based on the rubric.
In practice, we write multiple rubrics for content categories on which we want to steer GPT-4- launch behavior. The main dataset comes from our production traffic (with consent from users). We use our models (the Moderation API plus zero-shot GPT-4) and human reviewers to filter and classify prompts into content categories.
Personalization
The feedback loop from data to model improvement is, at best, indirect, for ChatGPT. However, the value of data is not just enhancing the models. Personalizing ChatGPT could be a powerful experience.
One way to do so is by using past conversations to provide context for future ChatGPT interactions. Another is by automatically crafting prompts tailored to different user segments. For instance, I strongly suspect that the initial GPT-3.5 powering ChatGPT was influenced by Filipino annotators. I grew up in the Philippines where writing English is unique — overly polite and indirect. American English is more direct, albeit full of idioms. Neither is better than the other. But it’d be nice if OpenAI automatically inserts prompts to tailor communication styles based on where the user lives. There are many other simple quality-of-life personalizations that OpenAI can build.
Does OpenAI have proprietary data?
As discussed above, the chat logs collected by OpenAI, while proprietary, are not directly helpful. GPT models, and most foundation models, are trained on publicly available data. That isn’t defensible. However, OpenAI has been taking steps to build a more proprietary dataset.
Pre-training
Over the past year, OpenAI has been chasing licenses from media companies to train GPT models on their data in exchange for millions of dollars a year. Here are some deals they’ve struck:
July 2023 — The Associated Press on Thursday said it reached a two-year deal with OpenAI. As part of the deal, OpenAI will license some of the AP’s text archive dating back to 1985 to help train its artificial intelligence algorithms.
July 2023 — Shutterstock is extending its partnership with OpenAI for six more years, which gives OpenAI a license to access additional Shutterstock image, video, and music libraries and associated metadata for training models.
Dec 2023 — Axel Springer and OpenAI have announced a partnership — not just a licensing agreement. The partnership allows ChatGPT to enrich users’ experience by adding recent content from Axel Springer’s media brands. The collaboration also involves the use of content to train OpenAI’s models
Jan 2024 — OpenAI is in discussions with media firms CNN, Fox, and Time to license their content
Fine-tuning
OpenAI’s Human Data Team is building a system that uses human experts’ guidance to teach our models how to understand difficult questions and execute complex instructions. They were recruiting “Expert AI Teachers” across a wide range of fields from biology to law to economics. What’s notable is they set a high bar for these teachers — they have to be at least in the 90th percentile of their field, with teaching experience, and must also possess a kind personality. OpenAI also hires Scale AI to gather more training data. The latter was recently hiring for “AI Training for K12 Teachers” to work on various writing projects including evaluating AI responses. While this particular job post could be for other foundation model companies, it is illustrative of companies spending money to gather high-quality proprietary data.
Is the ChatGPT experience hard to replicate? Growing to be
Three months ago, the answer would have been no. Replicating the ChatGPT experience would have just taken 5 minutes — fork a Replit repo for the front end and key in an OpenAI API. ChatGPT plug-ins were still shabby back then. But a lot has changed since OpenAI’s Dev Day in November 2023. ChatGPT is becoming more than a thin wrapper around GPT-4 with:
a proprietary native RAG experience for ChatGPT to respond based on files given to it
the ability to customize ChatGPTs with custom instructions and actions (which replaced plug-ins). In two months, users have created over three million GPTs.
and a GPT store to find & interact with other GPTs within the same UI. While it remains to be seen whether GPTs will get adopted, getting well-known brands to build GPTs is difficult to replicate. Here are some examples:
Personalized trail recommendations from AllTrails
Expand your coding skills with Khan Academy’s Code Tutor
Design presentations or social posts with Canva
Learn math and science anytime, anywhere with the CK-12 Flexi AI tutor
Does ChatGPT have a data moat?
Yes. Going back to the framework:
Is there a data flywheel? Indirect, for now.
Does OpenAI have proprietary data? Yes.
Is the ChatGPT experience hard to replicate? Increasingly so.
ChatGPT has a data moat & OpenAI is investing to widen it.
PS — While this essay focused on data moats, OpenAI’s widest moat is its product and AI talent. The pace at which their team has been releasing new products has users asking them to slow down. In 2023 alone they released: GPT-4 and GPT-4 Turbo, ChatGPT paid plans, cutting GPT-3.5 costs down by 90%, plug-ins, custom GPTs, and more. Finally, a point not emphasized as much by others is that GPT-4 finished training in the summer of 2022. Since then, there’s been plenty of healthy competition, but GPT-4 is still considered the best model. It became standard practice for researchers and software engineers to use GPT-4 to evaluate other models and even humans — how far are the answers to GPT-4’s? Holding the top spot in academic benchmarks is hard power. People unconsciously assuming that GPT-4 is the best model is soft power.
It will be fun to see who can dethrone OpenAI’s GPT models in 2024.