


Co-authored with Ben Lorica of Gradient Flow
What are foundation models?
Foundation models (FM) are a class of machine learning models that are trained on diverse data and can be adapted or fine-tuned for a wide range of downstream tasks. The term “foundation” is controversial among some researchers, but setting aside disagreements over terminology, these models already have had a significant impact. They are already used in large-scale applications in various areas including search, natural language processing, and software development.
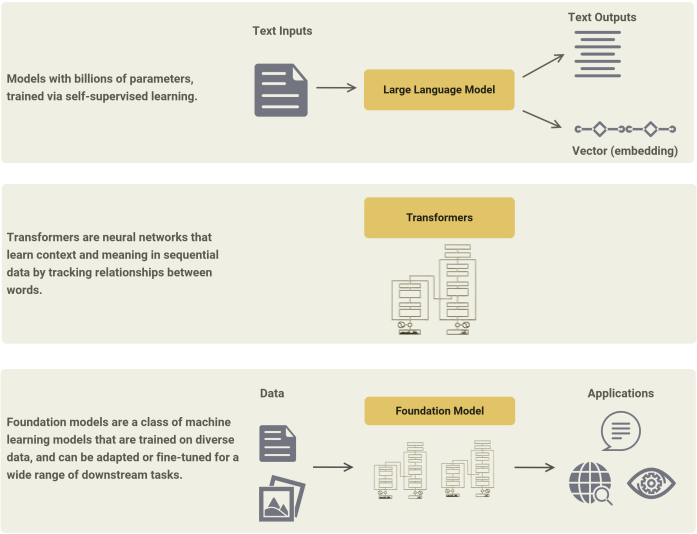
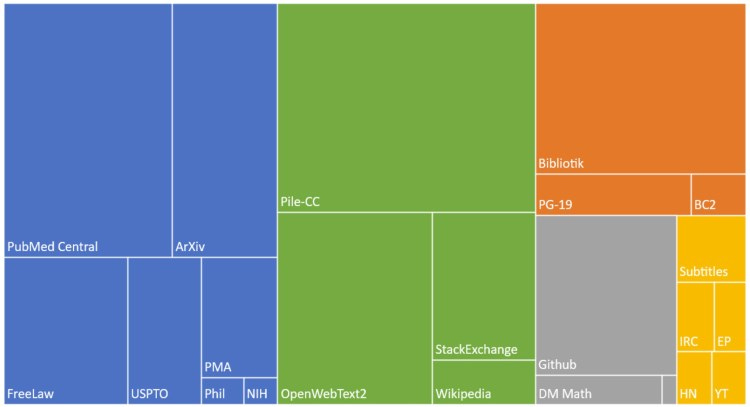
Scale is a key element of these models. Scale is enabled by improvements in hardware, the emergence of powerful models that can be parallelized (transformers), and the availability of large amounts of data for training (typically by self-supervised learning). In Figure 2 below, we show some of the open data sources used in training a large language model. The fact that such models are trained on a broad knowledge base makes them adaptable to a variety of downstream tasks.
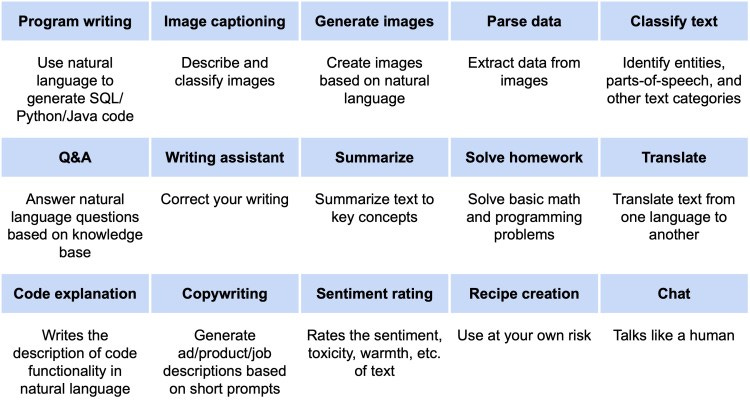
To illustrate their broad utility, we present a list of common NLP applications that foundation models are being used for today. Many of these applications (Q&A systems, chatbots, etc.) are well-known, but others, like code generation, are more innovative.
Why should investors and builders care
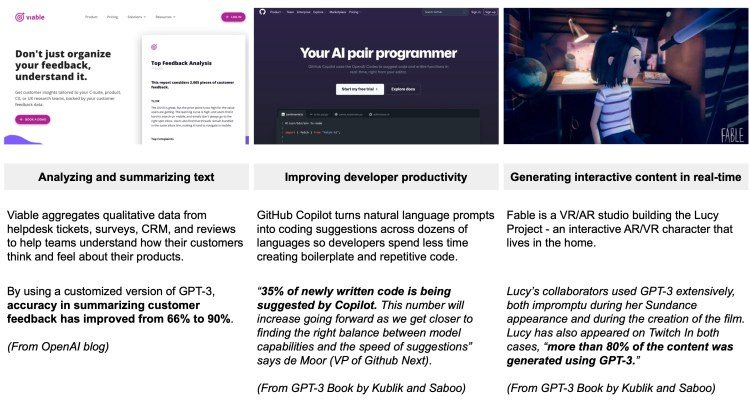
Foundation models are already powering the products we’re using daily: BERT is used in Google’s search engine. As we show in Figure 4 below, foundation models are not novel technologies looking for problems to solve.
Foundation models accelerate product development: In areas where foundation models are available, the focus shifts from training models from scratch, to acquiring data to fine-tune models for specific applications and tasks. FMs are also helping software engineers write code (e.g. Github Copilot).
Underlying technologies have made significant advances and models will only continue to improve: Google’s PALM was shown to be better than the average human across a wide range of language benchmarks from Q&A to code explanation to logical deductions. And researchers are just getting started: experiments with more efficient algorithms, new distributed computing tools, and multimodal models continue to yield steady improvements.
Foundation models could lead to more pegacorns: Deep learning breakthroughs led to startups with significant revenues (“pegacorns”). Most of the AI Pegacorns we uncovered are vertical or domain specific applications, not general purpose platforms We believe that foundation models will spur a similar wave of successful startups.
Startup Ecosystem
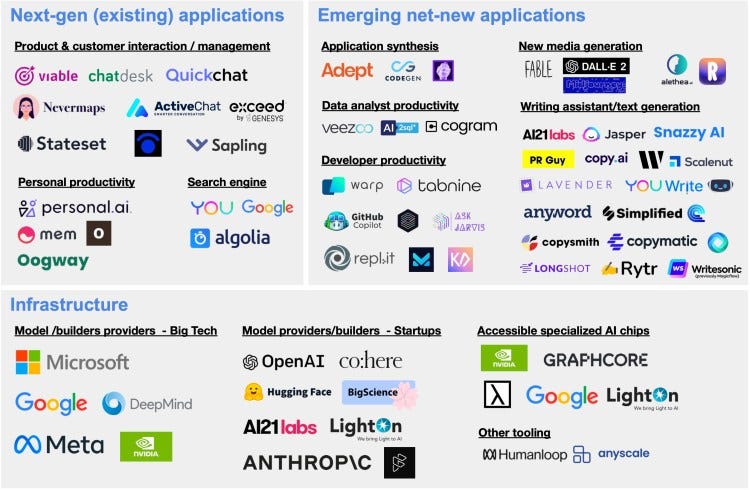
Given the potential of FMs, investors have begun funding startups in this space, most notably in companies building copywriting software. In Figure 5 below, we list over 60 companies that have raised over $3.8 billion to date and have been publicly described as using or building foundation models, which include large language models like GPT-3, Jurassic, etc.
Implications for product builders, entrepreneurs, and investors
Experiment with foundation model APIs: Decent models are becoming more available through SaaS providers or model hubs. You’ll likely still need to tune these models for your specific use case and application. Fortunately, computer vision and language models can be fine-tuned with fewer data to reach the level of accuracy needed for real-world use cases. “Off-the-shelf” models will also improve over time as vendors deploy larger base models.
Don’t confine yourself to text-based models or products: While NLP is the area where FMs have led to the most impressive applications, there are FMs in computer vision and speech that are beginning to lead to equally impressive applications.
Revisit your assumptions on what’s possible to build: Chatbots were the rage a few years ago but state-of-the-art technologies failed to live up to the hype. This created a stigma for chatbot startups. But with foundation models, creating more useful and more robust chatbots is now possible. For example, the CoQA (conversational question answering) benchmark measures the ability of models to understand a text passage and answer a series of questions in a conversational fashion. Several models have beaten the CoQA human benchmark since 2019.
Anticipate second-order effects: As applications built on foundation models grow, infrastructure, risk mitigation, and security needs will too. We’re still in the early phases of tackling questions like how to retrain models with new data efficiently, how to distinguish between machine versus human generated content, and what risk mitigation tools and processes will be needed.
Here’s the slide deck version of the guide where you can also find the spreadsheet of 60+ companies in the market map.