


I've been thinking a lot about memory lately - both human and artificial. Our memories shape who we are. Every conversation we have, every skill we learn, builds on this foundation of past experience. Without memory, we'd be starting fresh each moment.
This limitation is becoming apparent in AI systems as other aspects continue to progress. Since OpenAI’s o1 model release in September 2024, AI models have become remarkably good at reasoning through complex problems. They can analyze data, write code, and engage in sophisticated PhD-level discussions. But they have a fundamental limitation - they can't remember what they've learned from one conversation to the next without retraining . Like a brilliant person with no memory, they solve the same problems repeatedly without building on past experience.
As these reasoning capabilities become standard for the industry, what will set AI agents apart isn't their raw processing power, but their ability to maintain and learn from memory. This isn't just about storing information - it's about building systems that can understand context, remember past interactions, and apply those lessons to new situations. The memory layer will be a key differentiator in how AI agents understand and respond to us.
This article examines memory from multiple angles: how it shapes human cognition, how we're implementing it in AI systems, and how companies are building the technology to make AI agents that learn and remember.
Memory in humans
Personal: Memory is central to who we are. Our autobiographical memory - the collection of personal life events - creates a narrative connecting our past to our present, giving us a coherent sense of self. Research shows an interesting two-way relationship between memory and self-image: what we currently believe influences which past experiences we recall, and those memories in turn shape how we see ourselves today. Memory also shapes who we are to other people. Through our shared experiences, people remember us as their mother or father, their best friend or their enemy, the funny one at work or the quiet neighbor next door. Their memories of us are just as important as our own memories in creating who we are.
Social: People with strong memory capabilities - who easily recall facts, names, or past conversations - are often seen as intelligent and knowledgeable. Remembering information signals that someone is well-educated and quick-thinking, and it often goes hand in hand with problem-solving abilities. These individuals might also come across as reliable and attentive: think of a colleague who never misses a meeting detail or a friend who remembers every birthday - it shows conscientiousness and dependability. On the flip side, frequently forgetting things can have subtle social costs. When someone often forgets important details or asks the same questions repeatedly, others might question their organization skills or mental sharpness.
Practical: Memory underlies many of our cognitive functions. Far from being just a storage system for past events, memory actively helps us think about the future and make decisions. Drawing on past experiences lets us simulate possible future scenarios and apply lessons learned when facing choices. In fact, memory is involved in everything from problem-solving and communication to social skills like empathy - suggesting it's woven into nearly every aspect of complex thought. Without memory, we'd struggle to weigh options or learn from mistakes.
Memory in AI Agents
User Experience

When we look at AI agents, there are clear parallels between human conversation patterns and AI user experience. For an interaction with an AI system to feel natural, it needs some form of memory. Just as we remember what was said earlier in a conversation, an AI needs to retain context from previous exchanges to respond coherently. Without memory, the AI treats every query in isolation, leading to disconnected exchanges.
That's why it was frustrating to repeatedly copy-paste past conversations into ChatGPT and Claude when I want to bring in context from previous discussions. It feels like talking to someone with no memory of our past interactions. While ChatGPT now has a long-term memory feature that makes this better, Claude still doesn't have this capability.
Here’s another example, a voice assistant interaction: if you ask "Who called?" and the assistant says "Eric H.", you'd expect that following up with "Call him back" would make it dial Eric. Without short-term memory of context, you might get an annoying "Whom should I call?" response, forcing you to repeat information. This is why design guidelines emphasize maintaining conversational memory - it creates a smooth user experience and lets you reference earlier information efficiently. Memory transforms an AI from a basic question-answering tool into a conversation partner that can use pronouns and implicit references meaningfully because it "knows" what they refer to.
Memory also enables meaningful personalization. When an AI agent remembers your preferences, history, or goals, it can tailor its responses specifically to you. A personal assistant that remembers your favorite restaurants or previous travel plans can make more relevant suggestions. A recommendation system that recalls your past ratings can better predict what you'll like. In technical terms, long-term memory lets agents store historical data and user profiles, which directly improves their ability to personalize interactions. Instead of one-size-fits-all responses, a memory-enabled agent adapts to each user, maintaining continuity across sessions (it "remembers" you from last time) and awareness that extends beyond single interactions. Studies of conversational agents in healthcare show that such personalization leads to higher user satisfaction and engagement. Users stick around longer in conversations that acknowledge their personal context and don't make them repeat themselves. The dialogue quality improves because the agent's responses are contextually appropriate and consistent over time.
Memory in AI doesn't just produce better task performance – it shapes how users emotionally relate to and trust the system. An AI agent capable of remembering and learning over time tends to feel more human and empathetic.
For example, if a virtual assistant consistently recalls a user's preferences (like their food allergies or schedule constraints), the user will trust its suggestions more and feel a greater sense of rapport, much as we trust friends who remember our likes and concerns. Continuity builds relationship: a chatbot that references a user's previous messages ("I remember you mentioned last week you were feeling anxious. Are things better now?") demonstrates care in a way, thereby encouraging the user to confide and engage further. This human-like quality increase users' trust in the AI.
In contrast, a lack of memory can make an agent seem robotic or inattentive, undermining trust. Users often grow frustrated or disengage when they have to repeat information or when the AI fails to "recall" context that it should know. It breaks the illusion of interacting with an intelligent partner and reminds the user that the agent is just a machine following scripts. Especially in applications like healthcare, counseling, or personal assistants, trust is paramount – and trust is reinforced when the AI shows it remembers past interactions accurately. By retaining history, AI agents can also avoid inconsistent or contradictory responses, further improving credibility. All these factors contribute to a more user-friendly experience. Users are more likely to continue using, relying on, and recommending an AI service that remembers them.
Technology: AI Agent Framework Refresher
At a conceptual level, an AI agent has six core components, modeled after the human mind. Here's a simple breakdown of each:
For a deeper technical exploration, see:

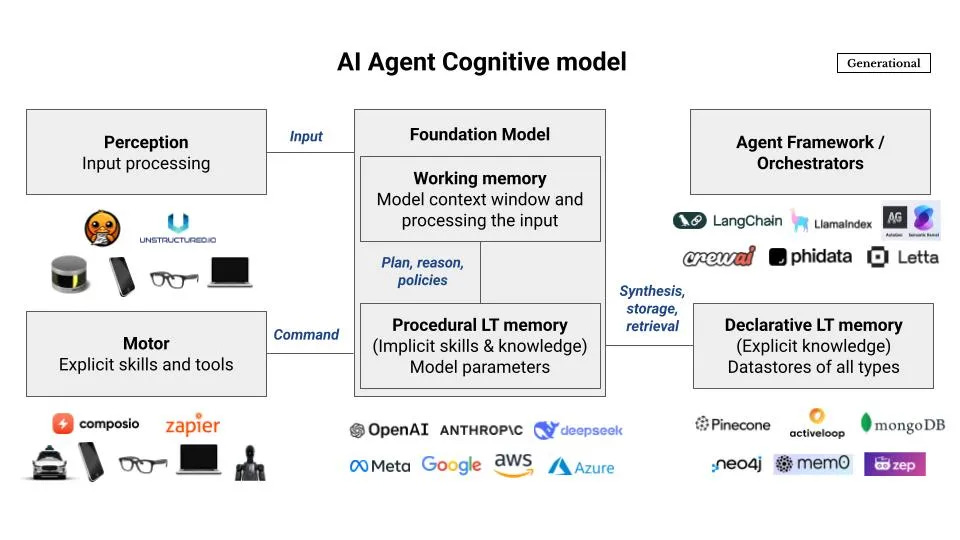
Perception: Converts raw data into formats the AI can process. Like human senses, it handles tasks like computer vision and natural language processing. Tools like Unstructured.io help convert formats like PDFs into data the AI can work with.
Working Memory: Think of this as the AI's mental workspace - temporary storage and active processing. Like how we juggle thoughts or calculations in our head, in AI this is similar to the context window in large language models, holding immediate inputs and retrieved information for processing.
Procedural Long-term Memory: This is where "how-to" knowledge lives. In AI, it includes the implicit knowledge built into the model during training, particularly post-training, like how to maintain response boundaries, follow instructions, reason through problems, and use tools.
Declarative Long-term Memory: Stores facts and events. In AI, this uses databases - think knowledge graphs for facts and vector databases for abstract data like image patterns.
Motor: Handles interactions with external systems. For AI, this means performing actions like sending emails or managing files, usually through APIs.
Orchestrator: Coordinates all the other components, managing:
Retrieval: Getting data from memory into working memory
Synthesis: Converting temporary data into permanent storage
Storage: Converting data into machine-processable formats
Planning: Organizing tasks and decisions to align with broader goals
Technology: Long Term Memory
While AI agents use different types of memory as shown above, let's focus on the challenge of declarative long-term memory - storing and retrieving information across conversations. When I first wrote about this topic 18 months ago, the working memory (context window) was quite limited - 4,000 to 8,000 tokens at most. The natural solution was external long-term memory using vector databases and improving how we orchestrated RAG. Since then, context windows have grown exponentially - Google's Gemini now handles up to 2 million tokens.
This expansion of working memory might seem to solve our problems - after all, we could theoretically fit 170 hours of conversation in Gemini's context window. But dumping everything into working memory fails for several reasons:
Just like humans can't perfectly recall hour-long conversations, raw context doesn't create useful memory
The quality of retrieval degrades with too much unfocused context
Processing large context windows remains computationally expensive
The core challenge in declarative long-term memory is providing the right context so the model can give the best answer for the user. This breaks down into three key problems:
Synthesis: How do you summarize memories?
Storage: How do you retain them efficiently?
Retrieval: How do you recall the right information at the right time?
There are generally three approaches to building these systems:
Plain text
Vectorization
Synthesized chat logs in structured form (table or knowledge graph)

Each approach has trade-offs, and they can be combined for hybrid RAG. For simplicity, plain text isn't practical because searching through raw text is inefficient. Let's focus on vectors and structured data.
Vector Storage: Technically, this approach converts text into numerical vectors using embedding models. Each chunk of text becomes a long list of numbers (usually 1000+ dimensions) that represent its meaning. When you need to find relevant information, you calculate how similar these vectors are to each other - like measuring the distance between points in space.
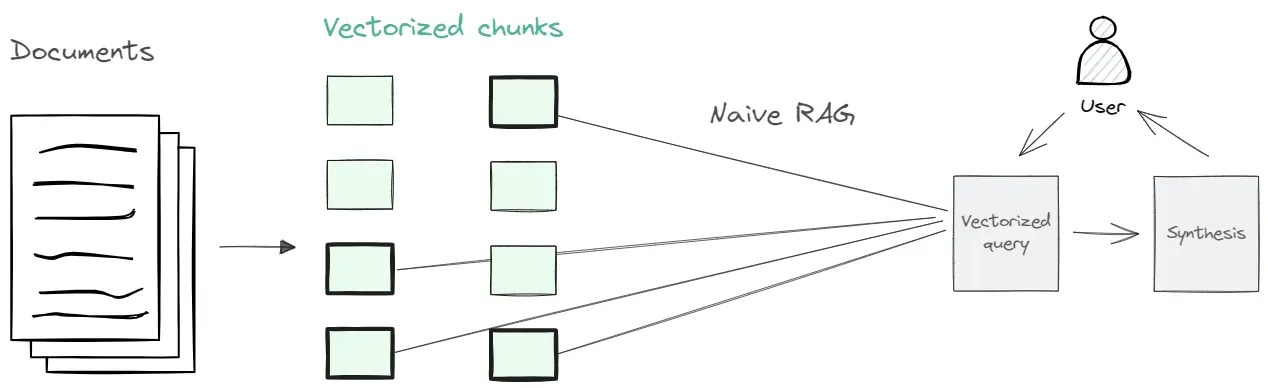
It's like having a huge pile of clothes and using similarity to find what you need - you might search for "something red and soft" to find your favorite sweater. It's quick to set up but can get messy when you have lots of items. Vector search is great for finding semantic similarity but doesn't understand relationships between pieces of information.
Knowledge Graphs: Technically, this approach stores information as a network of nodes (entities) connected by edges (relationships). Each node and relationship can have properties that describe them. When you need information, you follow these connections to find what you're looking for.
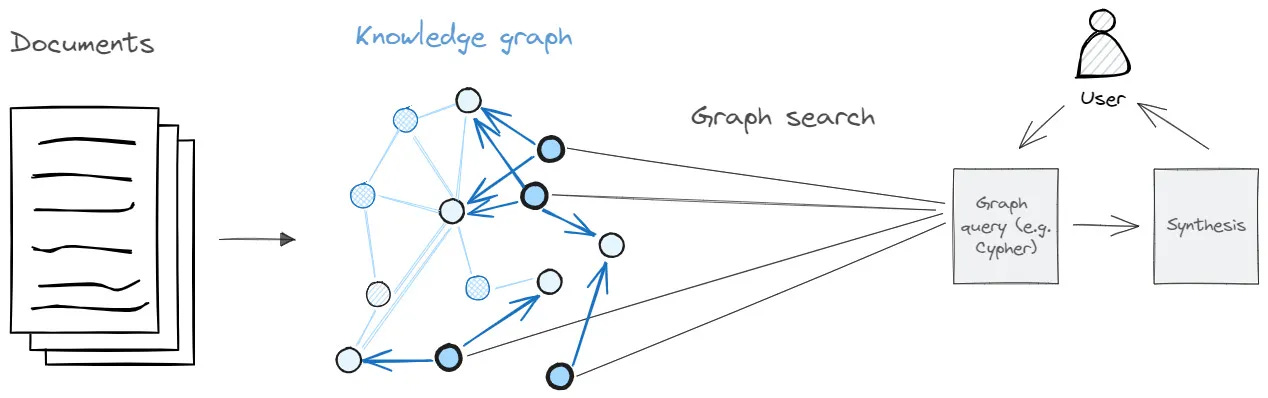
It's like an organized closet where everything has its place - shirts with shirts, pants with pants, and you know which items go together. It takes more work to organize initially, but finding things is more systematic. Knowledge graphs excel at following explicit relationships but require more structure.
Hybrid Systems: The most sophisticated systems combine both approaches: use vector similarity to find relevant content quickly, then use graph relationships to understand context and connections. This gives you both semantic search and structured relationships, though it requires more engineering effort. For example, when searching for project information:
Vector search finds semantically relevant documents
Graph traversal shows how these connect to people, deadlines, and dependencies
Together, you get both content and context
For a more technical comparison of vectors and knowledge graphs, see:

I lean toward knowledge graphs because they match how we think when we're being deliberate - in terms of categories, things, and relationships between them. This reflects what psychologists call System 2 thinking (slow, conscious reasoning). Though admittedly, most of our day runs on System 1 (fast, automatic responses). When I see my parents, I automatically greet and hug them. I don't consciously think "I see two people, these are my parents, parents deserve respect and love, therefore I should greet them." This aligns with industry practice that for 80% of cases, System 1-style processing (like vector search) works fine. For the 20% of cases needing more careful thinking, we need System 2-style processing (like knowledge graphs).
Recent research from Amazon and CMU offers valuable insights into how different memory approaches stack up. Their findings show that dumping everything into the context window (CoT LLM) performed much worse than any RAG system, despite Claude 3 Sonnet having a 200,000 token window. Graph-Only RAG was only slightly better than Text-Only RAG (vector RAG), showing about 5% improvement. Interestingly, agentic/self-reflective systems ReAct and Corrective RAG performed worse than expected. However, combining methods proved powerful - Text & Graph RAG and HYBGRAG (which adds self-reflection to Hybrid RAG) showed significant accuracy improvements.

For most applications, basic vector RAG works well enough. It's when organizations want to build exceptionally smart and personally tailored applications that they need structured data or knowledge graphs. While implementing knowledge graphs can be challenging, companies like Google and Glean have successfully deployed them to give them a competitive edge.
For a detailed exploration of knowledge graphs and how they fit into Google and Glean, see:

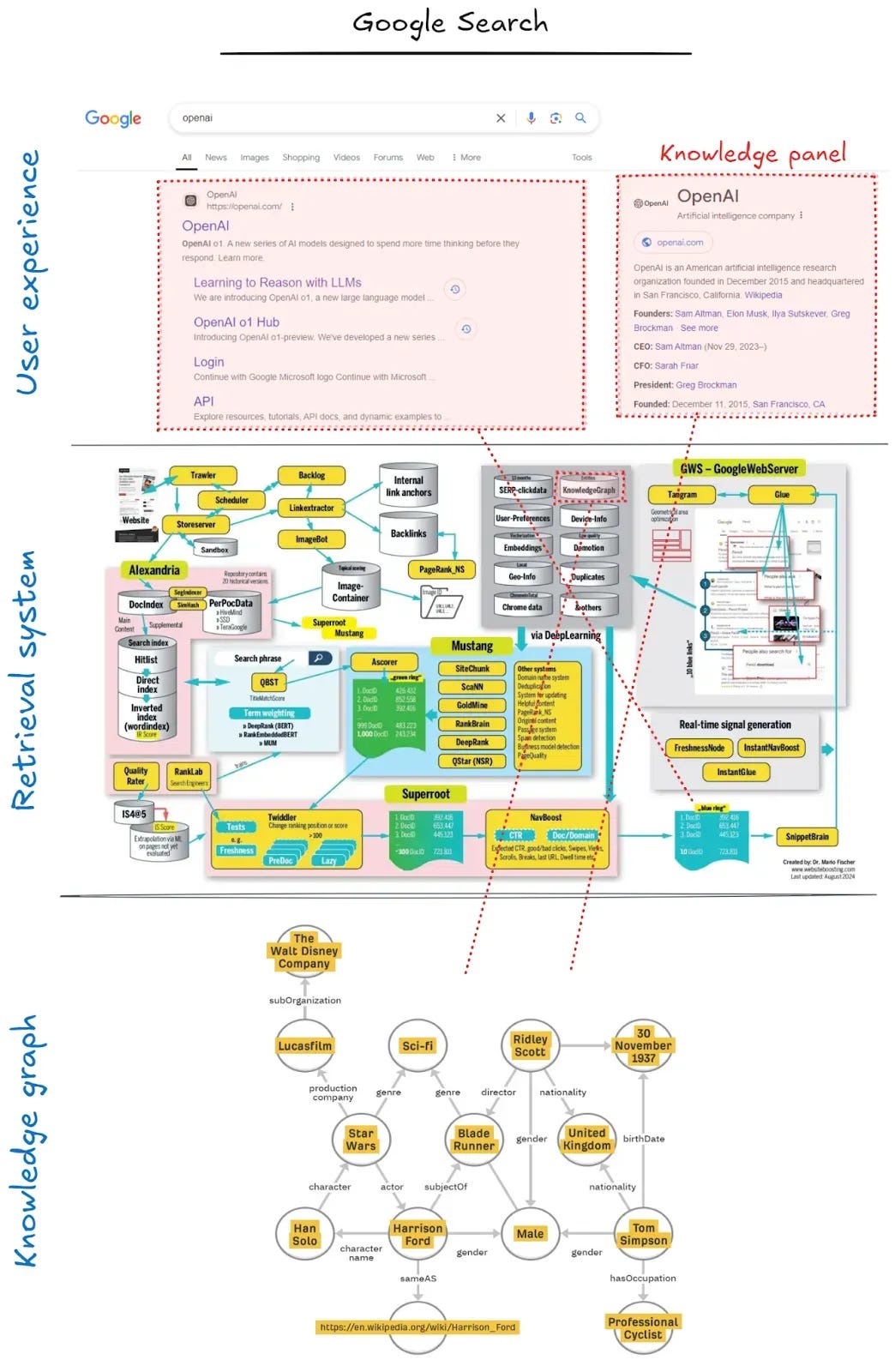
Another interesting study is done by Zep, one of the memory startups we'll discuss below. They compared their specialized memory system to the "dump everything in context" approach. Their system scored 18% higher while using only 1/10th of the processing time and 1/100th of the context tokens. For users, this means more relevant answers, faster. For developers, it means lower costs since they're not paying for extra input tokens.

Business
The memory layer is becoming a key focus among the most popular AI apps. OpenAI has been rolling out enhanced memory features that let ChatGPT store explicit memories and reference past conversations. This is a shift from their original approach where ChatGPT would start fresh with each conversation, though they did add basic memory capabilities in February 2024.
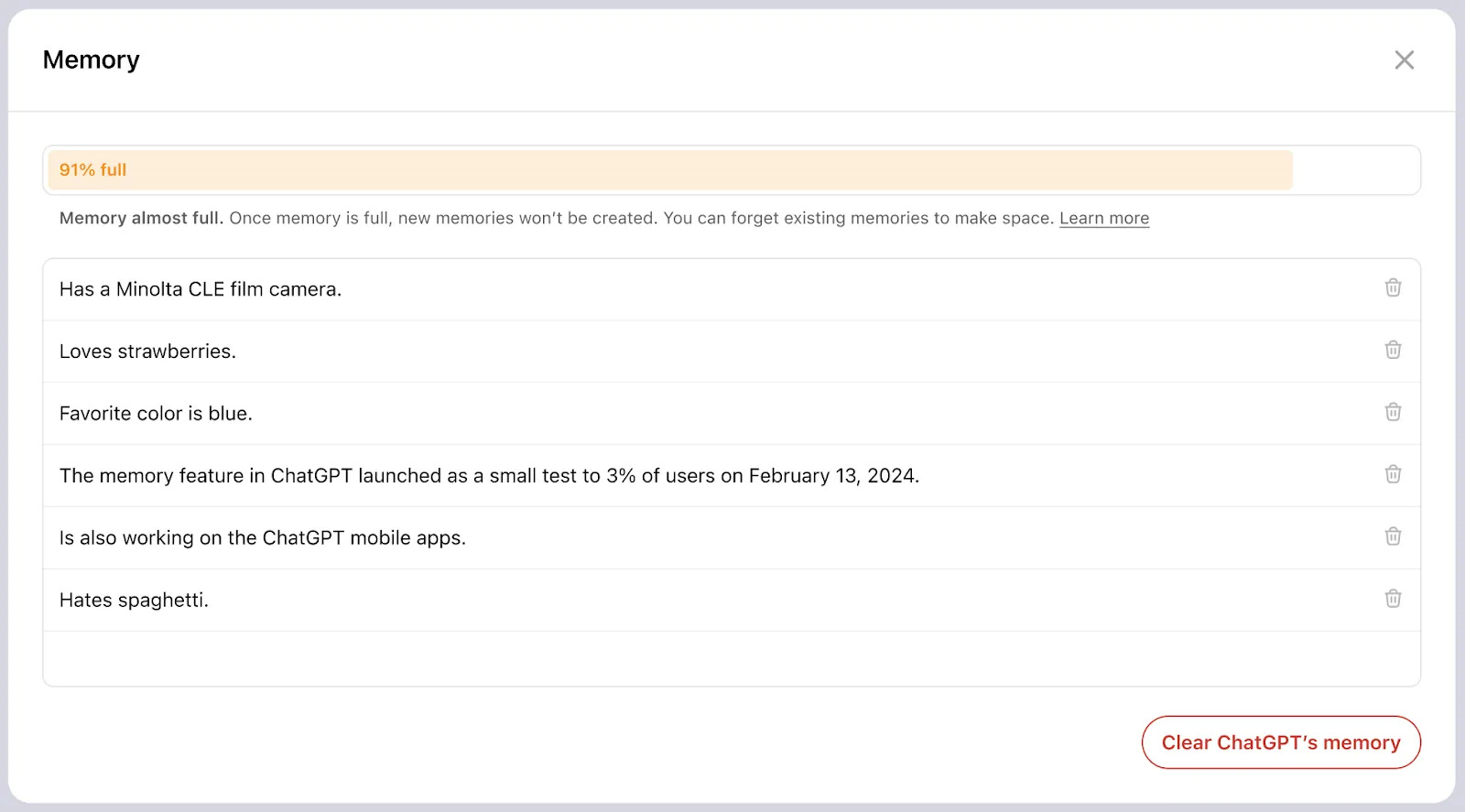

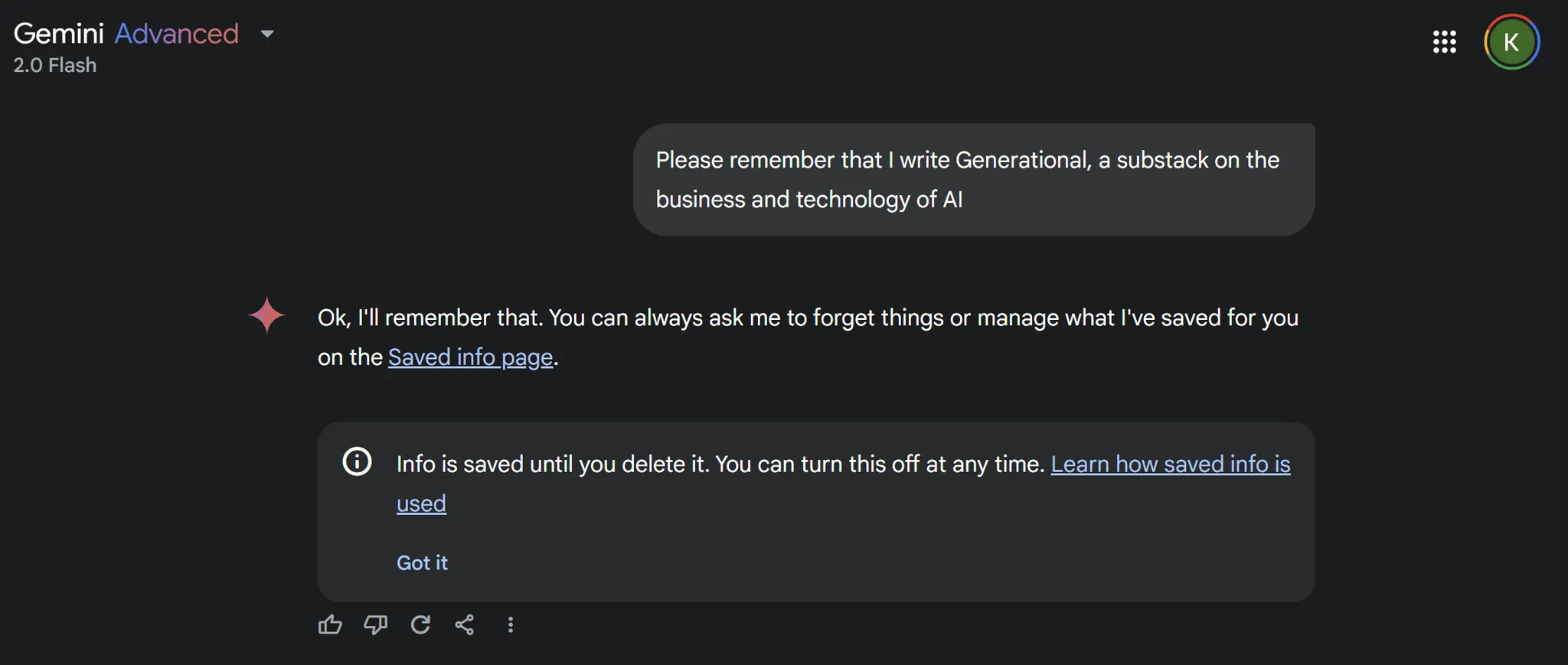
Similarly, Gemini incorporated memory features in November 2024. While OpenAI and Google are likely building their own memory systems (a technically challenging task), it's worth looking at startups offering memory as a service, particularly those implementing hybrid graph RAG. While any database could theoretically serve as memory, we'll focus on those using sophisticated hybrid approaches: Zep and Mem0. We'll also look at Letta, which treats working memory as a core feature in their agent framework, and Neo4j, the go-to graph database for AI products.
Other interesting companies and projects in the space but not profiled below: Cognee, WhyHow, Memary, Kuzu, Memgraph,
Zep (Zep 3K stars, Graphiti 2.1K stars)

Background & Founding: Zep was founded in 2023 in San Francisco as part of Y Combinator’s Winter 2024 batch. It emerged to build a “memory layer” for LLM applications, allowing AI agents to retain and recall past interactions.
Funding: The company has raised $3.3 million from Engineering Capital, Step Function, and founders & leaders at Vercel, Google, and several well-known AI companies.
Founders: Zep was founded by Daniel Chalef (CEO) – an engineer who previously founded KnowledgeTree and held senior roles at SparkPost. Chalef’s background spans engineering, data science, and enterprise software, guiding Zep’s technical vision.
Product & Technology: Zep offers a long-term memory service that developers can plug into their AI agents to store conversation history and retrieve relevant facts on the fly. Initially, Zep’s system extracted “facts” from chat logs and used a specialized RAG pipeline (semantic search + reranking) to surface relevant context. To overcome issues with purely semantic retrieval, Zep developed Graphiti – an open-source library for building temporal knowledge graphs from chat history. Graphiti dynamically captures entities and relationships from conversations (including changes over time), and supports hybrid search that combines vector similarity with graph traversal queries. This approach lets an AI agent recall context not just by semantic match, but also via connected knowledge (e.g. remembering that “X is Y’s manager” or how a user’s preferences changed). Zep’s memory API returns these relevant snippets or facts in milliseconds, without requiring the full chat history in each prompt.
Differentiation: Zep stands out for its temporal knowledge graph approach. Instead of just using vector embeddings or key-value stores, Zep automatically maintains a structured graph that updates as conversations develop. This captures context shifts and relationships over time (like noting that "the user previously preferred X but now prefers Y") - nuances that simple vector search might miss. By combining graph-based memory with semantic search, Zep aims for more accurate and explainable context retrieval, especially for handling changing facts and historical context in ongoing conversations.
Mem0 (25k stars)

Background & Founding: Mem0 was founded in 2023 and is based in San Francisco. The company is backed by Y Combinator and launched to tackle the stateless nature of LLMs by providing a persistent memory layer for AI applications.
Funding: The company raised a seed round of about $500K in April 2024, led by Y Combinator.
Founders: Taranjeet Singh (co-founder & CEO) and Deshraj Yadav (co-founder & CTO) lead the team. Singh’s background includes engineering and product stints at Khatabook (YC S18) and Paytm, as well as founding an AI tutoring app and co-creating the open-source EvalAI platform. Yadav was previously an AI Platform lead at Tesla Autopilot and is an AI/ML infrastructure expert who created EvalAI during his grad studies.
Product & Technology: Mem0 provides an open-source memory layer that makes AI assistants stateful. It stores user interactions, preferences, and other context so that an AI agent can “remember” past sessions. Under the hood, Mem0 uses a hybrid datastore architecture combining three components: a vector store, a key–value store, and more recently a graph store to represent relationships between entities, . When an AI query comes in, Mem0’s engine automatically extracts important information from prior interactions and uses a blend of graph traversal, vector similarity search, and key-value lookups to fetch the most relevant memories. This ensures the LLM is injected with the right contextual info (e.g. past user queries, corrections, or personal facts) without the developer having to manually prime each prompt with all history. The design goal is to improve personalization and reduce repetition, while minimizing prompt size by externalizing memory storage. Mem0 is open source and has a cloud offering of managed mem0 with premium features. The open source project has garnered over 22,000 GitHub stars and 500,000+ downloads.
Differentiation: Mem0 distinguishes itself through a unified hybrid-memory architecture and open-source approach. By natively combining graph, vector, and key-value stores, it handles both semantic and symbolic aspects of memory out-of-the-box. This differs from solutions that use only vectors or only graphs - Mem0 believes combining techniques leads to more personalized and cost-effective AI interactions.
Letta (15k stars)
Background & Founding: Letta emerged from UC Berkeley’s AI research community in 2024. It was spun out of the Berkeley AI Research Lab (BAIR) and came out of stealth in September 2024. The founding team had been researching AI agent memory before forming Letta as a company.
Funding: Letta raised a $10 million seed round in 2024, led by Felicis Ventures. The round also included participation from Sky9 Capital and Essence VC, as well as prominent angel investors such as Jeff Dean (Google DeepMind’s Chief Scientist) and the CEOs of Hugging Face, Runway, MotherDuck, dbt Labs, Anyscale, and Hex.
Founders: Dr. Charles Packer and Dr. Sarah Wooders co-founded Letta. They met during their PhD research in the Sky Lab at UC Berkeley, where they worked under professors Ion Stoica and Joseph Gonzalez who now serve as advisors to Letta. Packer and Wooders are AI researchers who co-authored the MemGPT paper – which introduced the concept of self-editing memory for LLMs – and have deep expertise in machine learning systems.
Product & Technology: Letta is building an end-to-end platform for AI agents with long-term memory. It has a popular open source project and is building a hosted service where developers can deploy stateful AI agents via an API. The platform is model-agnostic – developers can bring their own LLM while Letta handles the memory and agent logic. A key component is Letta’s Agent Development Environment (ADE), a web interface that lets developers design, debug, and monitor their agents’ reasoning steps and memory content. This ADE emphasizes white-box memory: developers can see exactly what information is stored and used at each step, and even edit the agent’s memory or prompts in real-time. Technically, Letta’s memory system builds on the MemGPT concept of self-editing memory: the LLM agent can write to and read from an external memory dynamically during a conversation. For example, after each user interaction, the agent can update its knowledge base (adding or modifying facts) which will persist into future sessions. By maintaining this stateful context, Letta-enabled agents aim to avoid resetting every conversation – they “remember” the user’s past instructions, preferences, or corrections.
Differentiation: Letta stands out by focusing on agent-centric memory and developer tools, backed by academic research. While other memory layers act as infrastructure, Letta provides a complete agent platform - essentially a turnkey way to deploy AI agents that learn over time. This comprehensive approach means they handle issues like agent derailment, reliability, and prompt management alongside basic memory storage. Their focus is on making it easy for developers to create stateful AI agents, rather than just providing memory storage. This makes them complementary to lower-level storage solutions - they could potentially integrate with vector or graph databases from other providers.
Neo4j (14k stars)

Background & Founding: Neo4j, Inc. is the oldest and most established company in this group, known as the pioneer of graph databases. It was founded in 2007 by Emil Eifrem (CEO), Johan Svensson, and Peter Neubauer. Neo4j’s early vision was to make data relationships a first-class citizen in databases.
Funding: Over more than a decade, Neo4j has raised approximately $580 million across multiple venture rounds. Notably, it closed a $325M Series F in 2021 at a valuation above $2 billion, one of the largest investments in database history. Investors in Neo4j have included GV (Google Ventures), One Peak, Morgan Stanley Expansion Capital, Creandum, and others.
Founders: Emil Eifrem, the CEO, is credited with sketched the first code of Neo4j and evangelizing the power of graph databases. Co-founder Johan Svensson has served in engineering leadership, and co-founder Peter Neubauer (who has since pursued other ventures) helped bring the database to market. The founding team’s background was largely in enterprise software and open-source development.
Product & Technology: Neo4j is a high-performance graph database management system that stores data as nodes (entities) and edges (relationships) with properties. In the context of AI and memory layers, Neo4j serves as a platform to build and query knowledge graphs – structured representations of facts that an AI can draw upon. Developers use Neo4j’s Cypher query language (or its GraphQL and Python integrations) to query complex relationships efficiently. For example, one can retrieve a subgraph of all information related to a user’s query, enabling multi-hop reasoning (traversing connections between concepts). Neo4j ensures ACID-compliance and scalability for large knowledge graphs, which is important for enterprise deployments. Recently, Neo4j has actively positioned itself in the GenAI space by promoting GraphRAG (Graph-augmented RAG) architectures. The idea is to combine Neo4j with traditional vector-based retrieval: a vector search might find relevant documents, and Neo4j’s graph can then add context by linking those documents to related entities or facts.
Differentiation: Neo4j's role in the memory layer space is as foundational technology rather than a specialized AI memory service. They stand out through maturity and capability - they're a proven platform with global enterprise adoption, suitable for production knowledge graphs with millions of nodes and relationships. Many other companies in this space use or integrate with graph databases like Neo4j under the hood. Unlike startups focused on chatbots or LLM agents, Neo4j is a general-purpose database adaptable to many uses (from fraud detection to recommendations, and now AI context storage). This means more integration work - organizations need to build their schemas and data pipelines - but it offers unmatched flexibility and powerful graph analytics through their Graph Data Science library.
this is also top of my mind - great article!
Great article. I have been looking for, but can't find discussions on how all of this impacts and is impacted by the hardware it is operating on. It would be great to get an analysis on the implications for memory and storage and the hardware systems.