


Databricks is the second company in Generational’s late-stage company series. This was fun to write. As part of the research, I got the Lakehouse and Generative AI Fundamentals badges from Databricks Academy. Disclaimer: I have a financial interest in Databricks. Don’t take this as investment advice.
In this deep dive, you’ll learn insights from conversations with many of Databricks’ customers and ex-employees. I want to thank Tegus for giving me access to their centralized expert call transcripts. With a platform as broad as Databricks, it is almost impossible to parse signal from the noise without primary research. If you’re curious about Tegus, try them out with this link.
Thank you to the 25 who joined in the past 2 weeks. Shout out to Gil Dibner and Harsh Khoont for referring new subscribers!

Databricks is the data & AI company. Founded by the creators of Apache Spark, the company has evolved from its roots in big data processing to a data intelligence suite covering the entire data & AI lifecycle. The company is helping over 10,000 customers, including iconic organizations like Adobe, Toyota, FDA, Shell, Conde Nast, and many more.
Why Databricks is a generational company
Product: Databricks' unified platform is designed to handle massive amounts of data, providing businesses with a seamless way to process, analyze, and gain insights from their data. The platform is based on open-source technologies giving customers optionality (which enterprises love) while also building proprietary optimizations across the entire stack to make the product faster, more stable, and cheaper to use than competing products.
Market: Databricks’ $126B addressable market will grow 17% annually over the next few years, creating ~$30B potential industry revenue annually. Databricks is also well-positioned in the fast-growing generative AI market, which is expected to grow 87% annually, creating ~$15B potential industry revenue annually.
Traction: Databricks’ revenue grew from $1M in 2015 to $1.6B in 2023, making it one of the fastest-growing companies in history. In spite of intense competition, the company is expected to continue growing by over 50% over the next two years.
Team: The company is one of the best-rated companies to work for, with a 4.4 Glassdoor rating and a 4.0 Blind rating. Most of the founders continue to be actively involved in the company and are respected in both industry and academia. Ali Ghodsi is one of the most well-regarded CEOs and was voted one of the best CEOs by the tough crowd at Blind.
Contents
Origin — The Spark that started it all
It all started with a research project at UC Berkeley's AMPLab in 2009. A team of seven UC Berkeley academics - Ali Ghodsi, Andy Konwinski, Arsalan Tavakoli-Shiraji, Ion Stoica, Matei Zaharia, Patrick Wendell, and Reynold Xin - came together to work on Apache Spark, an open-source distributed computing framework designed to be faster and easier to use than Hadoop MapReduce, the dominant big data processing framework then. The key innovation behind Spark was the concept of resilient distributed datasets (RDDs) - a way to divide big data into smaller chunks that can be processed faster across multiple machines while ensuring data is not lost if something goes wrong. This allowed Spark to achieve speeds up to 100x faster than Hadoop by caching data in memory instead of reading/writing from disk. But the goal was not just speed - it was to make big data analytics accessible to a wider audience. Programming MapReduce is painful. Spark is easier for developers to learn and program.
In 2010, Spark was open-sourced under a BSD (Berkeley) license. This allowed a community of contributors to grow around the project beyond UC Berkeley. The community around Spark grew rapidly. In 2013, Spark became an Apache incubator project and was promoted to a top-level Apache project in 2014.
As Spark's adoption grew, the founding team realized there was an opportunity to build a company around it. In 2013, the founders decided to start Databricks. The company‘s first product is a cloud-based notebook interface that allows customers to use Spark without all the complications of setting it up. They also continued to lead Spark's open-source development along with the community.
Under Databricks' stewardship, Spark adoption has skyrocketed and become the de facto processing engine for data engineering, data science, machine learning, and business intelligence in thousands of enterprises worldwide.
As the CEO, Ali Ghodsi is the face of Databricks. But he didn’t want to become the CEO in the first place. Neither did Ben Horowitz, their first investor board member. In 2015, then-CEO Ion Stoica decided to go back to his professorship at UC Berkeley and step down. Ali, who was VP of Engineering at the time, was chosen by the other founders to take over as CEO. But Ali did not want to, he wanted to continue being an academic. Ben also doubted whether Ali would be a good fit. But everyone else in the founding team thought Ali was the right person. So Ali took the mantle in 2016 on a one-year probation. Fast forward to today, Ali is one of the most respected CEOs and Databricks is one of the most iconic companies.
History — Four Phases of Databricks
Phase 1: Growing and commercializing Spark (2013-2017)
In the early days, from 2013 to 2017, Databricks focused on growing the Spark community and building out its commercial product. Spark moved to the Apache Software Foundation in 2013 and graduated to a top-level Apache project in 2014, driving significant community adoption. In 2014, Spark demonstrated its performance advantages by handily beating Yahoo's record on the Graysort big data processing benchmark, taking one-third the time with one-tenth the computing power.
The company launched its commercial product in 2015, providing a managed platform with collaborative notebooks, automated cluster management, a user-friendly UI, and integrations with cloud storage like Amazon S3. This simplified the deployment of Spark for big data analytics and machine learning. Databricks also organized the first Spark Summit conferences to bring together the growing Spark community.

Phase 2: Becoming Data + AI (2017-2020)
From 2017 to 2020, Databricks entered a phase of rapid growth and expanded its vision to become a unified platform for data and AI. The company formed a major partnership with Microsoft in 2017 to integrate Databricks with Azure cloud as a 1st party service, exposing Databricks to Microsoft's large enterprise customer base. As a 1st party service, Azure Databricks is natively integrated with Azure's infrastructure, security, and services, providing a seamless experience for users. For example, I was able to launch Azure Databricks in a few minutes but it took me over 30 minutes to configure Databricks to run on GCP.
Databricks expanded its product to support the full machine learning lifecycle, from data preparation to model training and deployment. In 2018, it launched MLflow, an open-source platform for the ML lifecycle, and renamed Spark Summit to Spark + AI Summit, reflecting its broader focus. More crucially, in 2019, the company contributed Delta Lake to the Linux Foundation, planting the seeds for its Lakehouse strategy.
Phase 3: Data Lakehouse Platform (2020-2023)
From 2020 to 2023, Databricks pioneered the concept of the data lakehouse, an open architecture combining the best elements of data lakes and data warehouses. The Lakehouse Platform became the centerpiece of the company's strategy, and its product suite expanded to cover more of the data lifecycle. Reflecting this emphasis, Databricks renamed its conference to Data + AI Summit in 2021.
The company launched Databricks SQL service in November 2020, bringing data warehouse capabilities to the lakehouse and enabling a wider audience of SQL users. This became one of their fastest-growing products, growing to a $250M run rate ~3 years after launch. Databricks also launched other lakehouse capabilities like Unity Catalog for unified governance and Delta Sharing for secure data sharing.
During this phase, Databricks also actively acquired companies to get talent and accelerate its product roadmap:
2020: Redash (data visualization)
2021: 8080 Labs (data exploration) and Cubonacci (data science)
2022: Datajoy (Sales/AI solutions) and Cortex (ML production)
2023: bit.io (data developer experience), Rubicon (AI serving), Okera (data governance), Arcion (data replication), MosaicML (LLM training)
Phase 4: Data Intelligence Platform (2023-present)
In June 2023, Databricks repositioned itself as the Data Intelligence Platform to make GenAI a main part of its platform. A central piece of this is Databricks IQ, a knowledge engine that learns the unique nuances of customers’ data allowing users to interact with their data in natural language. Furthering the GenAI push, Databricks acquired generative AI startup MosaicML for $1.3 billion, open-sourced a large language model called Dolly, built many GenAI features (e.g. vector search), and invested in another genAI startup Mistral. These moves aim to make it easier for enterprises to build GenAI applications on top of Databricks' platform.

Pain point — Workloads, Personas, Architecture
Databricks’ platform is expansive, so I won’t cover the pain points the product suite tackles in detail. Instead, we’ll go through the primary workloads data and AI professionals manage.
1. Data Storage
In the context of data and AI workloads, it's about storing vast amounts of data in a secure, reliable, and accessible way for analysis and processing.
Key Persona: Data Engineers and IT Administrators are the primary personas involved with data storage. Their job is to ensure data is stored efficiently, securely, and in compliance with regulatory requirements. They are responsible for selecting the appropriate storage solutions (like databases, data lakes, or cloud storage services).
Challenges: Managing the exponential growth of data, ensuring data security and privacy, achieving high availability and disaster recovery, and optimizing costs associated with data storage solutions.
2. Data Management
Data management involves data cleaning, enrichment, classification, and governance to ensure high-quality data.
Key Persona: Data Managers/Stewards play crucial roles here. They focus on creating policies and procedures for data handling and usage, ensuring data quality, and maintaining data governance requirements.
Challenges: Ensuring access to quality data, managing data across systems and formats, and adhering to evolving regulatory requirements.
3. ETL (Extract, Transform, Load)
ETL is a process that involves extracting data from various sources, transforming it into a format suitable for analysis, and loading it into a final target database or destination. It's a foundational process for consolidating, cleaning, and preparing data for analysis.
Key Persona: Data Engineers are the key persona. They design and implement ETL processes, ensuring data is accurately extracted, transformed, and loaded into the destination systems for further analysis.
Challenges: Handling large volumes of data from diverse sources, ensuring the integrity of data through the transformation process, optimizing performance to reduce processing times, and managing the complexity of ETL workflows.
4. Data Orchestration
Holistic management and coordination of end-to-end data workflows, pipelines, and tasks. It encompasses a variety of operations, including but not limited to ETL, to ensure seamless data movement and integration across various platforms and systems.
Key Persona: Data and ML Engineers are central to orchestrating data pipelines. They design, implement, and monitor automated workflows that ensure data is processed and available where and when it's needed.
Challenges: Ensuring reliability and scalability of data pipelines, managing dependencies between different data processes, monitoring pipeline performance, and troubleshooting failures.
5. Business Intelligence
Business Intelligence (BI) involves analyzing data to extract actionable insights that inform business decisions. SQL is a programming language used for managing and manipulating relational databases, a common tool in BI processes.
Key Persona: Data Analysts are the primary personas. They use SQL and other BI tools to query, analyze, and visualize data, creating reports and dashboards that help businesses make informed decisions.
Challenges: Integrating data from multiple sources, ensuring data accuracy and consistency, designing effective data visualizations, and keeping up with the fast pace of business demands are significant challenges.
6. Machine Learning
Machine learning systems learn from data, identify patterns, and make decisions with minimal human intervention. It involves training models on data sets to perform ML tasks (like prediction and classification) and serving the models in production to inform decisions or power product features.
Key Persona: Data Scientists and Machine Learning Engineers are the key personas. They develop, train, and deploy machine learning models, working closely with data engineers to ensure they have the quality data needed for model training.
Challenges: Acquiring and preparing high-quality training data, selecting the appropriate algorithms and models, and managing the computational resources required for training and inference.
The roles within these infrastructures are highly interconnected, with data engineers laying the foundation for reliable data pipelines, data analysts uncovering insights from processed data, and data scientists building advanced predictive models. Machine learning engineers then operationalize these models, enabling their deployment and continuous improvement in production environments. Each of these personas uses a collection of tools that collectively form the data & AI architecture, which often is a complicated maze. Andreessen Horowitz’s blueprints provide the best overview of a unified data and AI infrastructure. In the images below, each box represents a software category and where it fits in the data lifecycle (sources to output). Databricks’ product suite covers most boxes except being the data source and having data labeling capabilities.

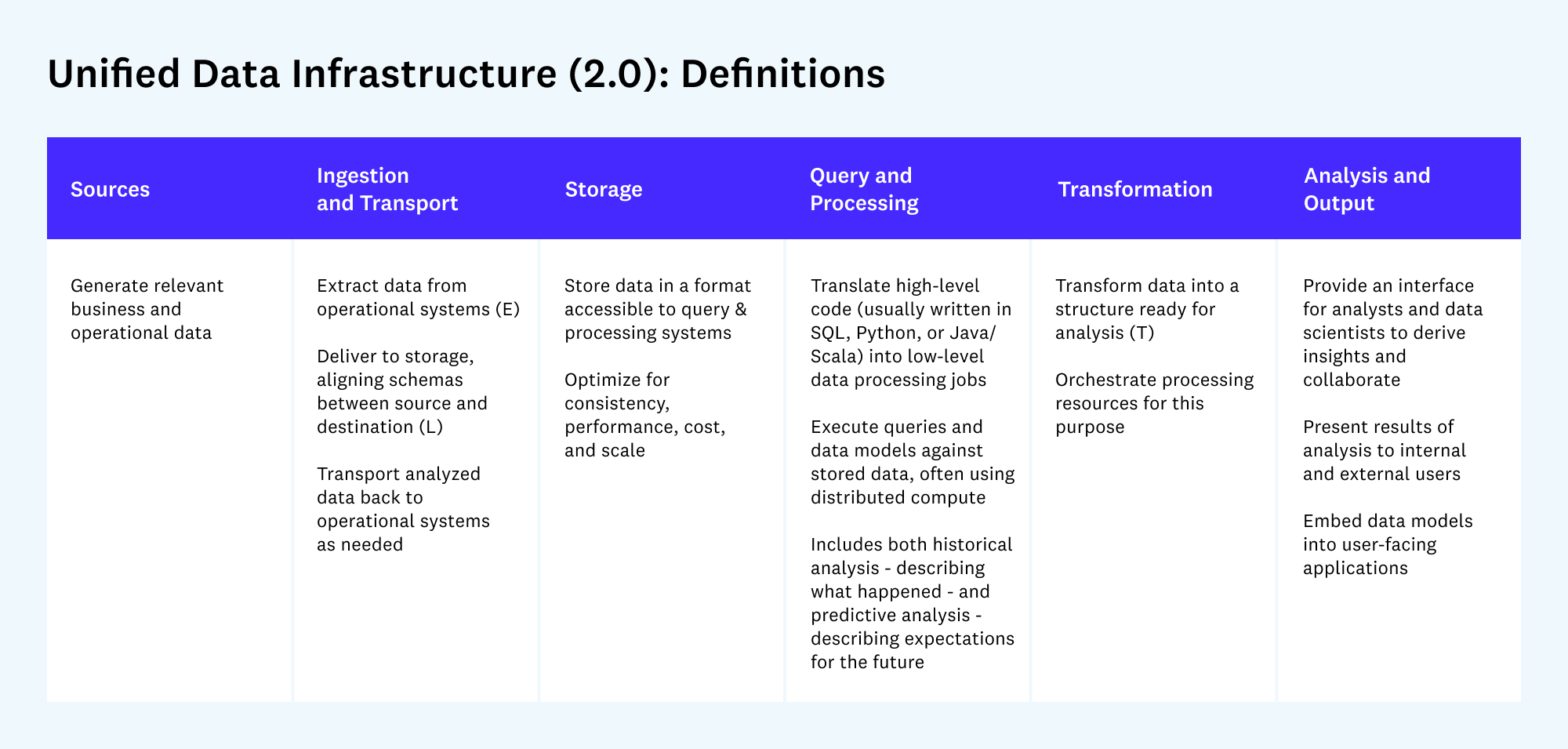


Product — Data Intelligence Platform


Databricks is a unified, open analytics platform for building, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions at scale. The Data Intelligence Platform is structured into several layers, each providing specific functionalities that interconnect to form a comprehensive solution. Going through the detailed diagram above is outside the scope. Instead, we’ll go through the key products loosely mapped against the primary workloads discussed in the previous section.
How Databricks works (why not just directly use open source on AWS/Azure/GCP)
Databricks runs on their customer’s cloud infrastructure (AWS/Azure/Google Cloud aka cloud service providers or CSPs). Under the hood, when customers deploy Databricks, it sets up a workspace to manage and deploy cloud infrastructure on customers’ behalf. This includes setting up compute clusters or SQL warehouses that are configured with Spark.
Many of Databricks’ services are built on open-source. While any developer can run these directly in any of the CSPs, Databricks abstracts away the complexity of setting up, maintaining the infrastructure, optimizing the configurations, and putting a collaborative unified interface on top. A lot of the optimizations are underpinned by the Databricks Runtime, a set of software artifacts that run on clusters managed by Databricks. These optimizations include, but are not limited to:
Proprietary enhancements that significantly improve the performance of Spark workloads, potentially offering gains of up to 5x over open-source Spark
Databricks Enterprise Security: Enhances security with features such as data encryption at rest and in motion, fine-grained data access control, and auditing
Databricks Runtime for Machine Learning: Includes machine learning libraries and tools, optimized for ML workloads. While it leverages Spark for data processing, it also includes libraries like TensorFlow and PyTorch for deep learning
Photon: a high-performance query engine that runs SQL workloads and DataFrame API calls faster, delivering up to 12x speedups
Delta Lake (Data Storage)

Delta Lake is the optimized storage layer that provides the foundation for tables in a lakehouse on Databricks. It can store any type of file, such as images, documents, audio/video, etc., in its data directories alongside the structured data files. Users can create Delta tables that contain references/pointers to the unstructured data files stored in the data lake storage (e.g., Azure Blob Storage, AWS S3, etc.). Databricks Delta Lake differs from the open-source Delta Lake project in that it includes proprietary features and optimizations specific to the Databricks platform.
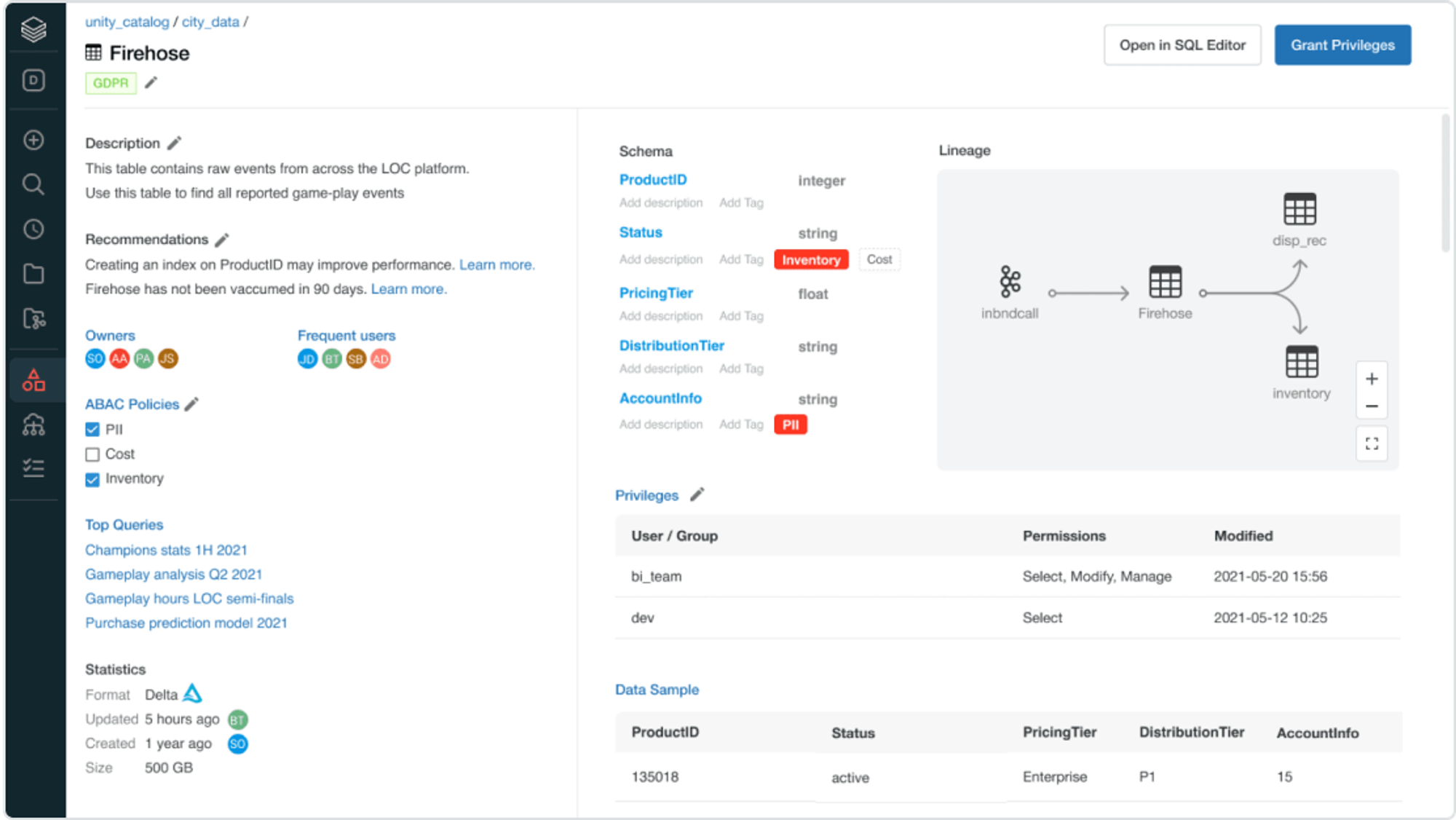
Unity Catalog is a unified governance solution for data and AI assets. The key features include a single place to administer data access policies that apply across all workspaces and a built-in auditing and lineage that captures user-level audit logs and tracks how data assets are created and used across all languages. It also offers data discovery tools that allow users to tag, document, and search for data assets.
Data Intelligence Engine
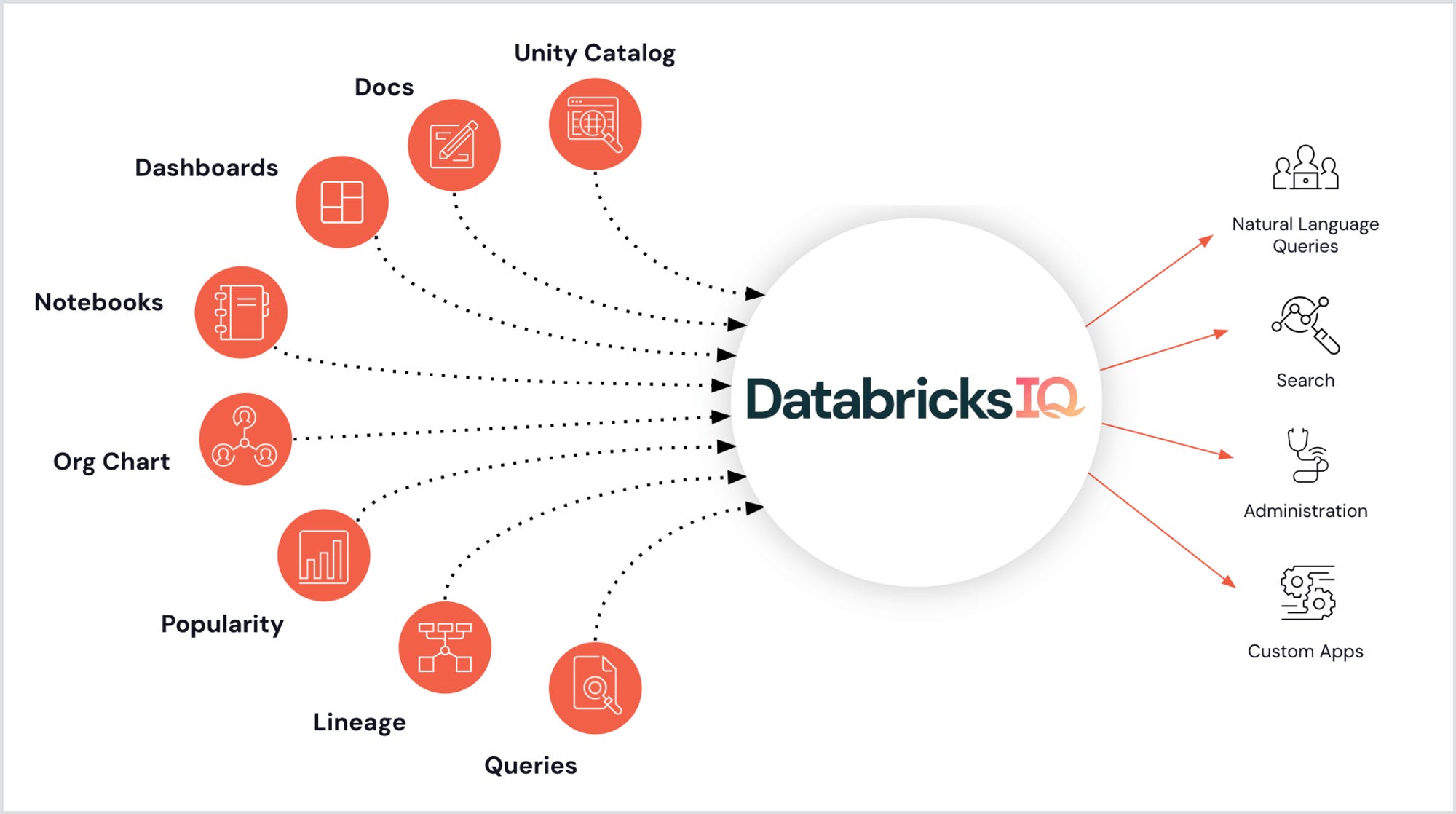
The Databricks Intelligence Engine, also known as DatabricksIQ/LakehouseIQ, is the platform's brain. It uses AI to understand the semantics of customers’ data, usage patterns, and org structure. This powers Databricks Assistant, an AI pair programmer, and improves in-product search by automatically describing assets in Unity Catalog. My favorite part is that DatabricksIQ will be available as an API, which can power all sorts of applications.
Databricks AI (Machine Learning)

Databricks AI is a comprehensive suite that allows users to build, experiment, and productionize machine learning models. It can be bucketed into two buckets: end-to-end (classical) machine learning and generative AI. The end-to-end ML capabilities encompass a full machine learning operations (MLOps) workflow with MLflow, which includes automated machine learning (AutoML), monitoring, and governance. The GenAI portion is anchored by MosaicML, which Databricks acquired. MosaicML developed efficient methods to reduce the cost of training and customizing large language models (LLMs), making these capabilities more accessible to a broader market. Customers can develop custom LLMs and serve them in production.
Delta Live Table (ELT)

Delta Live Tables (DLT) is an ETL and real-time analytics tool. It simplifies data ingestion and automates the creation of reliable data pipelines. DLT automates and orchestrates data ingestion, transformation, and management tasks, allowing users to define transformations using SQL or Python. DLT also supports data quality enforcement through expectations, which define the expected quality of data and specify actions for records that fail to meet these standards.
Workflows (Data Orchestration)

Databricks Workflows is a managed orchestration service designed to facilitate the definition, management, and monitoring of multitask workflows for ETL (e.g. with DLT), analytics, and machine learning pipelines. Workflows provide intelligent ETL processing with AI-driven debugging and remediation, ensuring end-to-end observability and monitoring of data processing tasks. Workflows can trigger based on schedules, file arrivals, or continuous runs to ensure that jobs are always up-to-date.
Databricks SQL (BI)
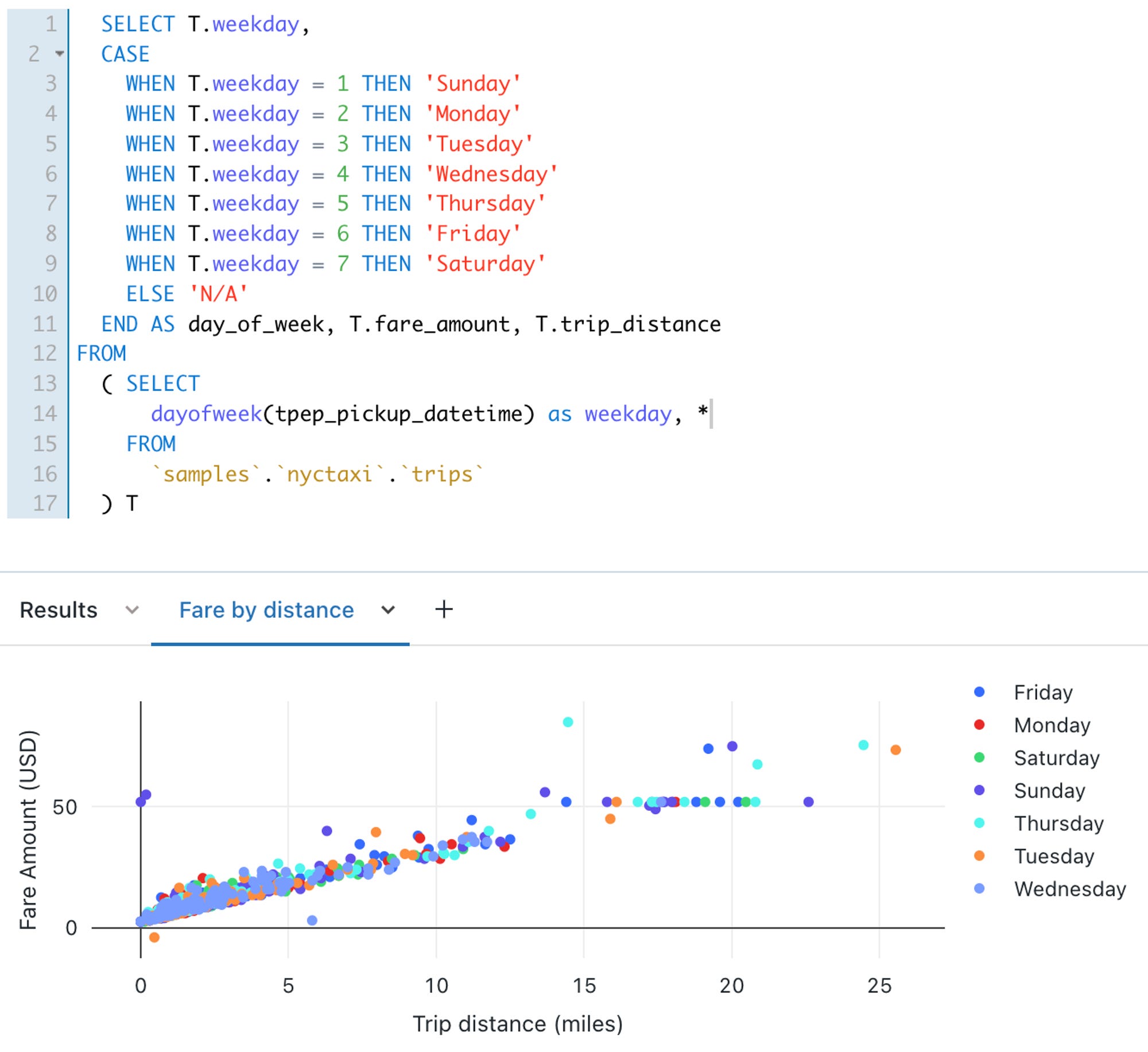
Databricks SQL is the collection of services that bring data warehousing capabilities in a lakehouse architecture. It has an in-platform SQL editor and dashboarding tools that allow team members to collaborate with other users. Databricks SQL also integrates with a variety of tools (e.g. Tableau) so that analysts can author queries and dashboards in their favorite environments without adjusting to a new platform.
Aside from these, there are two other products that are worth noting: Databricks Marketplace and Lakehouse Federation.
Databricks Marketplace

Databricks Marketplace is an open marketplace where anyone can obtain data sets, AI and analytics assets—such as ML models, notebooks, applications, and dashboards—without proprietary platform dependencies, complicated ETL, or expensive replication.
Lakehouse Federation

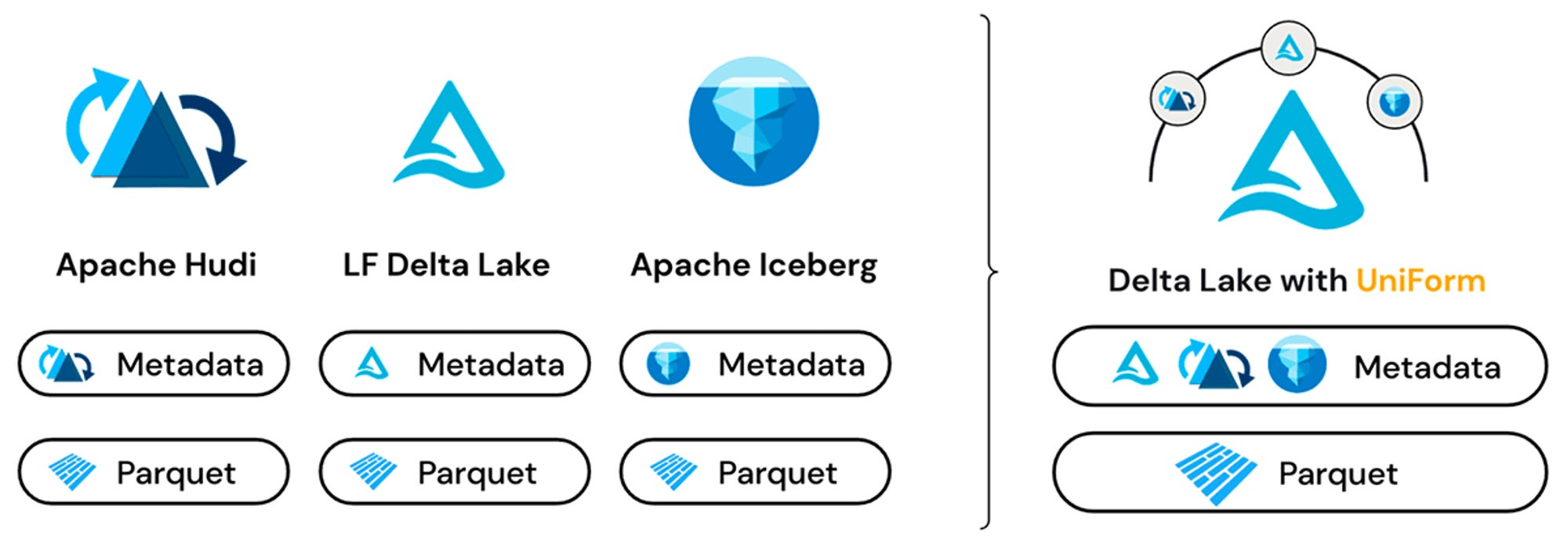
This is probably my favorite recent product. If customers are not going to consolidate their data on Databricks, they can still access their data through Databricks. The Lakehouse Federation capability can query against external data sources and currently integrates with PostgreSQL, Amazon Redshift, Snowflake (!), Azure SQL Database, Azure Synapse, and Google’s BigQuery. Databrick’s ambition of unifying the data estate go beyond just proprietary systems. With Delta UniForm (short for Delta Lake Universal Format), Databricks (and technically anyone using Delta) can read (and eventually fully manage) all popular Lakehouse formats.
Market Opportunity — $126B growing $25B a year
Databricks’ plays in the following analyst-defined markets:
Database management system is a product used for the storage and organization of data typically with defined formats and structures.
Data management software consists of tools to achieve consistent access to and delivery of data.
Analytic platforms are data science platforms for analysts to analyze data and build models
Enterprises are expected to spend ~$30B more each year in these systems, representing a large opportunity for Databricks to grow into. Generative AI tools, in particular, are going to be a material growth driver, with the relevant GenAI categories doubling almost every year in the near term, adding ~$15B in revenue opportunity annually. There’s some overlap between the two figures but the point stands that Databricks has a large market opportunity to continue growing into.
These numbers are based on analysts surveying organizations on how much they spend on different tools. It is not a pie-in-the-sky TAM figure but is based on actual and projected spend.

Competitive Landscape — Snowflake, CSPs, Startups
Databricks’ key competitors can be grouped into three:
Snowflake (or data platforms in general)
Cloud service providers (Azure, GCP, AWS)
Purpose-built tools
Databricks vs Snowflake
There is a rivalry between Databricks and Snowflake. While there are other data platforms, such as MongoDB, the narrative is primarily the competition between red and blue.
The rivalry intensified in 2020 when Databricks launched the Lakehouse architecture, encroaching into Snowflake’s territory. This even elevated to an unusual public tit-for-tat on official company blog posts when Databricks claimed to set the world record for a data processing benchmark, and Snowflake claimed foul because the assessment was not fair. Snowflake is also going after Databricks’ workloads. Snowpark first launched in 2021 allowing developers, data engineers, and data scientists to run non-SQL code. It supports Python and Scala for processing data pipelines, it also has a DataFrame API for data manipulation similar to Spark. Just from the name, Snowpark is a wordplay on Spark. In 2023, Snowflake launched Notebooks to address more of the ML workflow. While both seem to have a lot of overlap, there are key differences:
Databricks leans AI and engineers, while Snowflake leans toward BI and analysts: Databricks is the preferred tool for data scientists and engineers. Snowflake is for data analysts. Snowflake is also the preferred tool to just dump clean data. That said, both are trying to after each other’s core persona.
The quotes below are edited excerpts from Tegus’ platform.
Customer / Director of Data Insights at a large telecom company — So basically, both of the tools have very large presence [in my company]…we allow the users to have a different choice. Generally speaking, in chief data office organizations, we prefer to use Databricks, because the majority of us are data engineers or data scientists or software engineers. We like that environment. But from the business unit, majority of them prefer to use Snowflake. For those hardcore, very power-intense, compute-intense calculation, transformations, we use Databricks. And then for those more business-oriented scenes, we use Snowflake.
Customer / CTO at a large financial services company — You can actually get faster performance, I think, on Databricks if you know what you're doing. I think that's why the Snowflake released Snowpark because they understood that in some high-performance use cases where you need in-memory analytics, they were not as competitive.
So I would say that's a clear winner for me is Databricks. But at the same time, the folks who are like, just click around kind of user, maybe for them it's okay. Like, maybe they're not as concerned with performance as much as like the data science folks who have like large pipelines and large data sets to analyze.
Ex-employee & current service partner / Data engineering consultant — People think it's like Databricks versus Snowflake. It's actually very common for companies to have both where they use Snowflake for the data warehouse that powers all their business intelligence and all their analysts use that, and then they would use Databricks for more data engineering style work or like that the data scientists or data engineers or Python heavy users would want to go in and use.
Databricks has a broader product suite that is also modular: Adopting Databricks is easier because it be plugged into almost any data stack and used for any workload. A customer can have any data store, even if its Snowflake or AWS Redshift, and still use Databricks for data processing and AI/ML. The modularity also extends to Databricks’ open-source compatibility, having been built on top of major OS projects.
The quotes below are edited excerpts from Tegus’ platform.
Ex-employee / Sales executive — As a seller of Databricks, one of the easiest ways for us to get a foot in the door was, "I'm not going to ask you to change everything you're doing. We'll fit into your existing user flow and take over that one part. Maybe you only want to use this for your data ingestion, or you want to use this for your ML models". That's definitely a big focus area, not just from the open-source perspective, but also from the ease of use and scalability perspective. It makes a decision maker's decision a lot easier if there are already existing connectors or plug-ins or simplified ways to get started with their existing ecosystem and just plug Databricks in there.
And by the way, if the customers ever don't like Databricks, they can always revert back to an open source. They’re not locked into Databricks. The risk mitigation that came to that narrative compared to Snowflake was actually really significant particularly when we engaged IT in the sales process.
Customer / CTO at a large financial services company — The other big thing is Databricks is built on a lot of open-source technologies so that I know that if something horrible happens and Databricks gets acquired by Oracle, like my Halloween scenario. I'll still have a way to run stuff using open-source software. So I'm actually feeling much better about like going in with Databricks because it's better to have , potential options in the future versus like Snowflake, which is locked in some kind of ecosystem, but then Databricks also gives me some capabilities on-prem too.
Databricks vs CSPs
The CSPs Microsoft Azure, Google Cloud Platform, and Amazon Web Services are coopetitors. Similar to Databricks’ broad plug-and-play platform, the CSPs can also do the same. AWS has Sagemaker for AI/ML, Redshift for data warehouse, Glue for ETL, and Athena for BI. Azure and GCP have their own counterparts. They’re all well resourced competitors but also partners since Databricks directly on top of customers’ cloud infrastructure. Among the three CSPs, Azure is noteworthy because it launched a direct competing product, Microsoft Fabric, while also offering Databricks as a 1st party service. Customer conversations point out that Databricks is more scalable and stable than CSPs’ native products and Microsoft Fabric is better suited for smaller workloads. That said, Databricks’ closest cloud partner might be its biggest competitor.
The quotes below are edited excerpts from Tegus’ platform.
Customer / VP Cloud Architecture at a large insurance company — So we evaluated AWS data warehouse, Azure data warehouse, Google data warehouse and Databricks. And we found that Databricks is very cloud-agnostic. It has better scalability. On paper, on checklist, all the cloud providers do provide all those features. But when you go into deep analysis and depending on the use case, you will find that scalability in Databricks is more efficient.
Customer / VP AI/ML Apps at a large media software company — So my company uses Databricks heavily for mostly the compute because earlier services like Azure or AWS do not have a very good compute layer and our clusters were failing all the time. And Databricks provided a very good stable alternative, especially since they're owner of Spark and our team uses Spark heavily. So the Spark clusters were very stable and reliable on Databricks. While the cost is slightly higher for Databricks, the experience and the stability we got were very much well worth it because all our time went into making the application rather than debugging the systems that we do not own.
Global system integrator / Data architecture lead at a top 3 GSI — First of all, the Databricks is the god of capacity. Instead of EMR and SageMaker, Databricks is more robust. To give you an example. Azure has a data pipeline to do the ETL work, to curate the data, you need some logic to be created. But they have some bindings there. You cannot give everything. You cannot build everything in the Azure data pipeline. You need to bring Databricks if there is a complex pipeline. If there's complex logic is there, if there's a complex rule is there, it's really hard to implement that logic in Azure data pipeline. Same thing is for EMR or SageMaker.
Customer / Staff solutions architect at a large telcom company — I think that probably, the simplest way to put it is that Fabric as it stands today is best designed for small to medium power -- like BI teams that are trying to expand their data capabilities without necessarily having the technical like deep dive know-how in order to administer a lakehouse. There's a number of features that are missing that, I think, are necessary for it to be an enterprise like data platform product.
Customer / Principal data scientist at a large telecom company — I think we already make like some decision to move some workflows that require low latency to Fabric eventually. We think that approximately like 20% of all workflows will go with Fabric in span of next two years, maybe. With Fabric, we can go like even with Python or SQL to create those kinds of workloads. For future projects maybe like even up to 40% of all projects will go with Fabric.
Purpose-built tools
Aside from Snowflake and the big CSPs, Databricks also competes with point solutions, primarily startups. In a way, you can think of Databricks as bringing in together all the point solutions and optimizing it in a unified experience.
Databricks AI Notebooks: Domino Data Lab, Hex, and many others
Databricks AI MLFlow: Weights & Biases, etc.
Workflows: Astronomer (Airflow), Dagster, Prefect, etc.
Databricks SQL: Dremio, Starburst (Presto) etc.
Delta Live Tables: dbt, Matillion
Unity Catalog: Alation, Atlan, Acryl (DataHub)
Delta Lake: Tabula (Iceberg), OneHouse (Hudi)
Team — One of the best
Databricks has ~5,500 employees at the end of 2023 and growing. It has a 4.4 Glassdoor rating and a 4.0 Blind rating, which is among the best. Databricks is a large company with an extensive leadership bench so we will only go through the C-Suite that Wall Street will focus on.
Ali Ghodsi (CEO and co-founder) is responsible for the company's growth and international expansion. He previously served as the VP of Engineering and Product before taking the role of CEO in January 2016. In addition to his work at Databricks, Ali is an adjunct professor at UC Berkeley and one of the creators of Apache Spark.
Andy Kofoid (President, Global Field Operations) brings nearly three decades of experience building high-growth software businesses. Andy is respondible for all aspects of the Databricks customer journey, from brand awareness to renewals. Prior to Databricks, Andy served as the President of North American Sales at Salesforce, a $12B+ business unit with over 8,000 employees.
David Conte (CFO) leads all financial and operational functions for Databricks. He has more than 30 years of finance and administration experience in multinational public and private companies within the technology industry. Most recently, David served as CFO at Splunk where he took the company public and helped it grow from $100M in annual revenue to more than $2B.
But it is also worth noting that six of the seven founders are still executives in Databricks and very much active in Databrick’s growth (go browse their blog posts). Matei Zaharia is CTO and a board member, Reynold Xin is Chief Architect, Ion Stoica is Executive Chairman, Patrick Wendell is VP of Engineering, and Arsalan Tavakoli-Shiraji is SVP of Field Engineering. The only one who is not an executive anymore (but still is an advisor) is Andy Kowinski, who went on to co-found another amazing AI company Perplexity AI.
Financials — One of the fastest growing in history
Databricks grew from $1M to $1.6B revenues (not ARR) in 8 years, making it one of the fastest growing companies in history, along with a healthy gross margin of 80% and marketing-leading NRR of 140%. Databricks expects to continue growing at >50% and be cash flow positive by 2025 / fiscal year 2026.

Valuation — Historically rich, a deal looking forward
Wall Street analysts will compare Databricks to Snowflake. The key difference between the two financial profiles is the mix of growth and margins. For Snowflake, while growth has decelerated to mid-20s % (which is still fast relative to most companies), it is has ~30% free cash flow margin. At their scale, that’ll be over $1B in cash they can reinvest annually into growing the company. In contrast, Databricks expects to burn cash for another 1-2 years but grow at a faster pace of over 50%. In today’s market, there is still a higher premium attached to growth. Databricks’ $43B series I valuation looks rich relative to near-term financials but is fairly valued or even cheap a few years out, considering the expected growth.
